- Published on
基于字典的跨域神经机器翻译数据增强
huawei Technologies,2020
Dictionary-based Data Augmentation for Cross-domain NMT
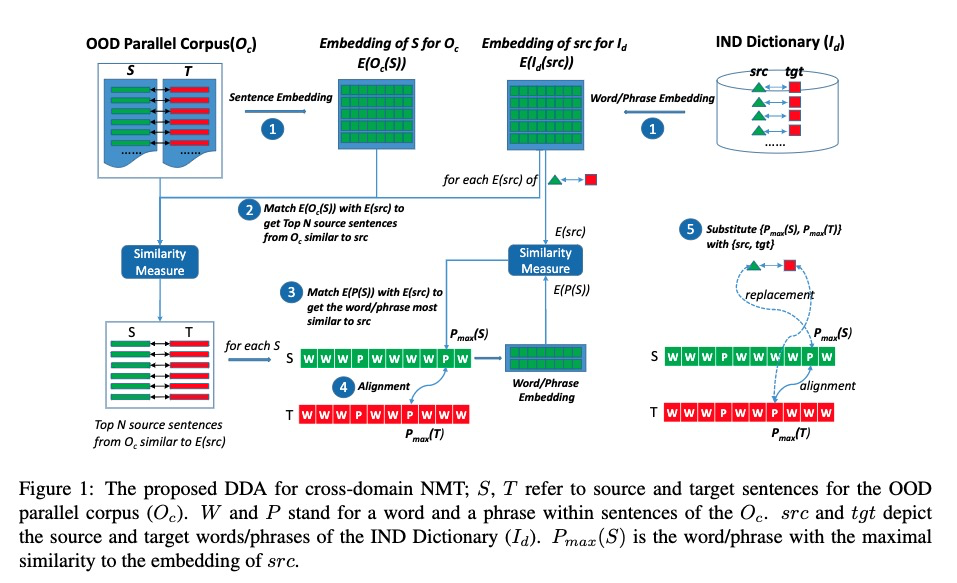
主要目标是使用平行领域字典$I_d$和OOD非领域平行语料$O_c$去创建伪领域平行语料$G_c$。步骤包括短语句子embedding,匹配,对齐,替换。思路比较简单。从OOD非领域平行语料库中选择句子作为主模板,根据相似单词,从领域词典中在特定位置植入领域术语。
step1: 计算$I_d$领域字典的word/phrase embedding和 非领域平行语料$O_c$的sentence embedding。
Step2: 根据领域字典的word 或parse的embeding匹配OOD中的句子embedding,选出OOD中的top N句子
Step3: 对OOD的source sentence中匹配与领域字典src最相近的单词或短语
Step4: 根据对齐模型在source sentence对应的target sentence中找对对应单词短语
Step5: 分别用领域字典的src和tgt替换OOD句子中的指定位置。
思路比较简单,算法如下:

Phrase and Sentence Embedding
使用pretrained multilingual的bert-as-service计算领域词典和非领域数据的embedding。模型细节:
Model details: a 12-layer encoder stack, 768-hidden, 12-heads, 110M parameters. Trained on cased text in the top 104 languages with the largest Wikipedias.
Phrase-sentence Matching
短语句匹配的目的是从OOD非领域平行语料库中选择句子作为主模板,从领域词典中植入领域术语。
使用faiss根据领域字典src embedding找出非领域数据中的最相似的N个句子(余弦相似度)。
Phrase Matching, Alignment and Substitution
使用textblob提取短语(当然这些几乎都是名字),相互比较,根据余弦相似度选择最相似的phrase。
对齐模型使用fastalign在OOD数据上进行训练。
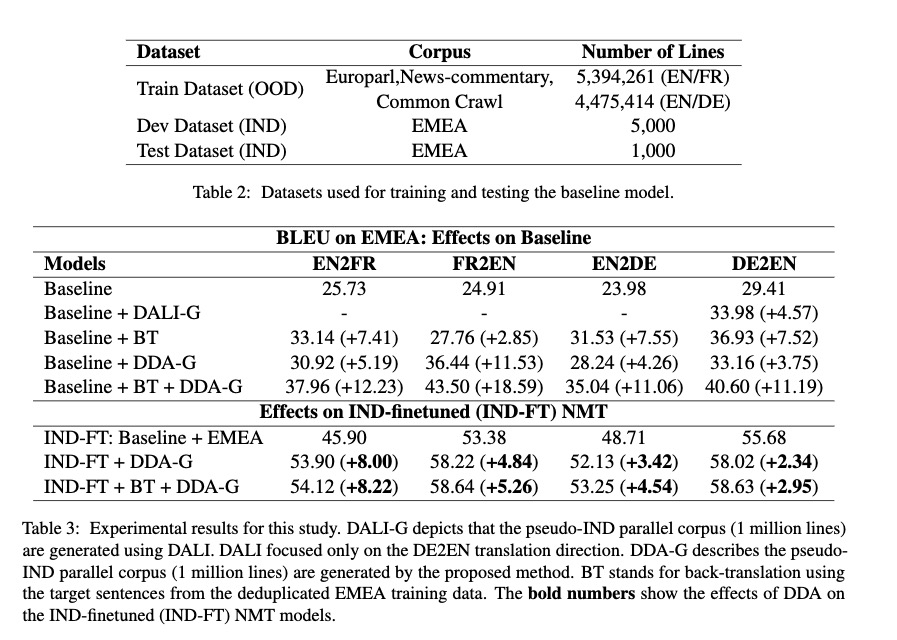
Experiment settings
领域数据SNOMED-CT包含36809(EN/DE)和36306的(EN/FR)
DALI NMT模型训练使用非领域数据和DALI(短语翻译模型)生成的伪领域数据(100万数据量)
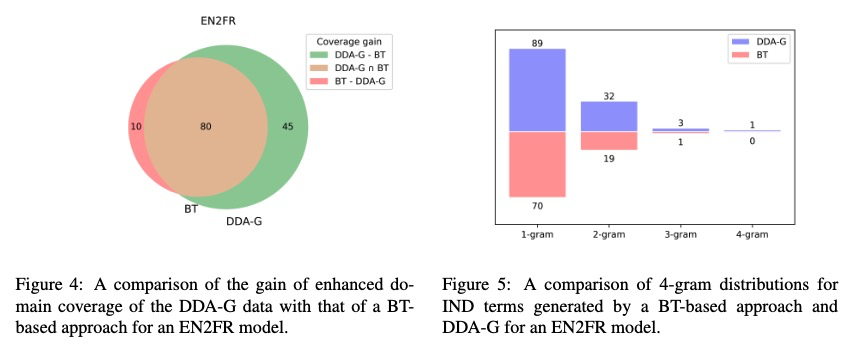
Further Analysis
使用1-5唯一的ngram来表示领域覆盖,下图可以看到DDA-G可以提供更有效的覆盖增强