- Published on
使用SMT特征提高NMT-2016_AAAI_百度
Improved Neural Machine Translation with SMT Features 2016年 AAAI 百度
Abstract
nmt常见存在OOV问题(需要确定的词表),并且在decoder阶段缺乏翻译所有source words的机制,模型更倾向于短的翻译,虽然流利但是不充分。
作者在log-linear 框架下组合了n-gram语言模型和翻译模型特征。在NIST 测试集中英方向提升了2.33 BLEU score
Introduction
2016年NMT的问题:
- OOV问题(但是现在有BPE了,缓解了开放词表的问题)
- NMT解码器缺乏一种机制来保证所有的源词都被翻译,并且通常倾向于短翻译。这有时会导致翻译不足,而不能传达源句的完全含义。
- NMT模型不能利用大规模的单语数据
目前的NMT框架很难在模型中添加有效的特性来进一步提高翻译质量。作者提出在对数线性框架下将SMT特征和NMT模型集成来改进NMT。组合了三个SMT特征:翻译模型,单词奖励特征,n-gram语言模型。
翻译模型采用基于短语的翻译模型在单词对齐的语料上进行训练。
单词奖励特征控制着翻译的长度。
n-gram模型提高目标单语句子的句子流畅性。
作者说明自己设计的优点:
- 在log-linear框架下使NMT系统可能很容易的扩展。有效的集成SMT。
- 在单词对齐的语料中使用IBM模型,根据翻译概率估计生成了单词翻译概率表添加到了log-linear框架中。单词翻译表不仅可以处理OOV问题还可以评测源单词和目标单词的关系
- 奖励机制,青睐长翻译(这里可以对beam search进行优化)
- 训练n-gram语言模型去提高翻译质量。用于在decode阶段选择候选。浅层的融合是使用语言模型对rerank
Background
介绍了RNN和log linear Models
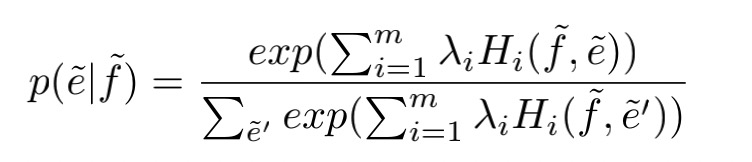
$H_i()$是特征方程,$\lambda_i$是权重
log-linear NMT
对于NMT来说,作者相信集成SMT特征可能能够帮助提升翻译的质量,单词翻译表可以提升单词的翻译,unknow的低频次。语言模型可以提高句子的局部流利度。
Feature Definetion
- RNN encoder-decoder feature,就是NMT根据源语言信息和上一步解码信息生成当前token的一个条件概率估计。
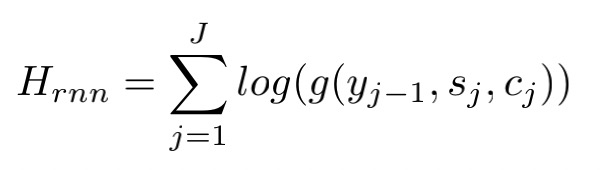
- 双向单词翻译概率表,在每一步的解码过程中,估计目标单词语与源单词的翻译概率。
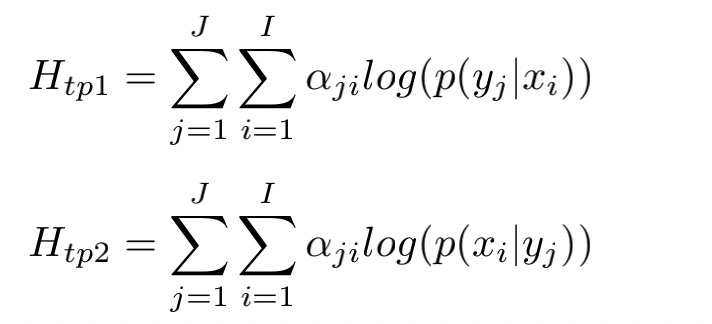
$\alpha_{ji}$是源语言和目标语言单词软对齐的权重,由RNN给出,$P(y|x),P(x|y)$是单词对齐双语语料(使用GIAZ++)中单词翻译概率。通过共现的次数作为分子,计算概率
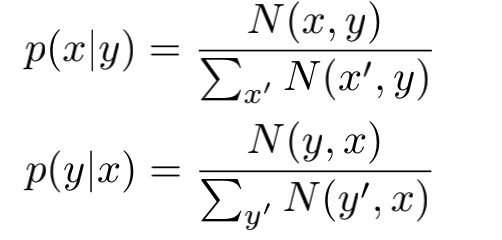
- n-gram语言模型,通过目标单语数据进行训练,
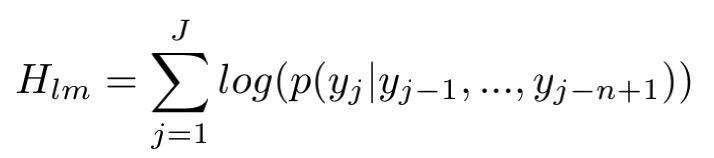
- 单词奖励特征,就是目标句子中的词数
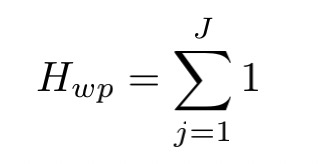
Handling the OOV problem
解决OOV的问题,作者首先根据根据RNN的对齐估计概率找出相应的source word,然后根据单词翻译表获得对应的翻译。最后的翻译结果根据log-linear 模型决定。
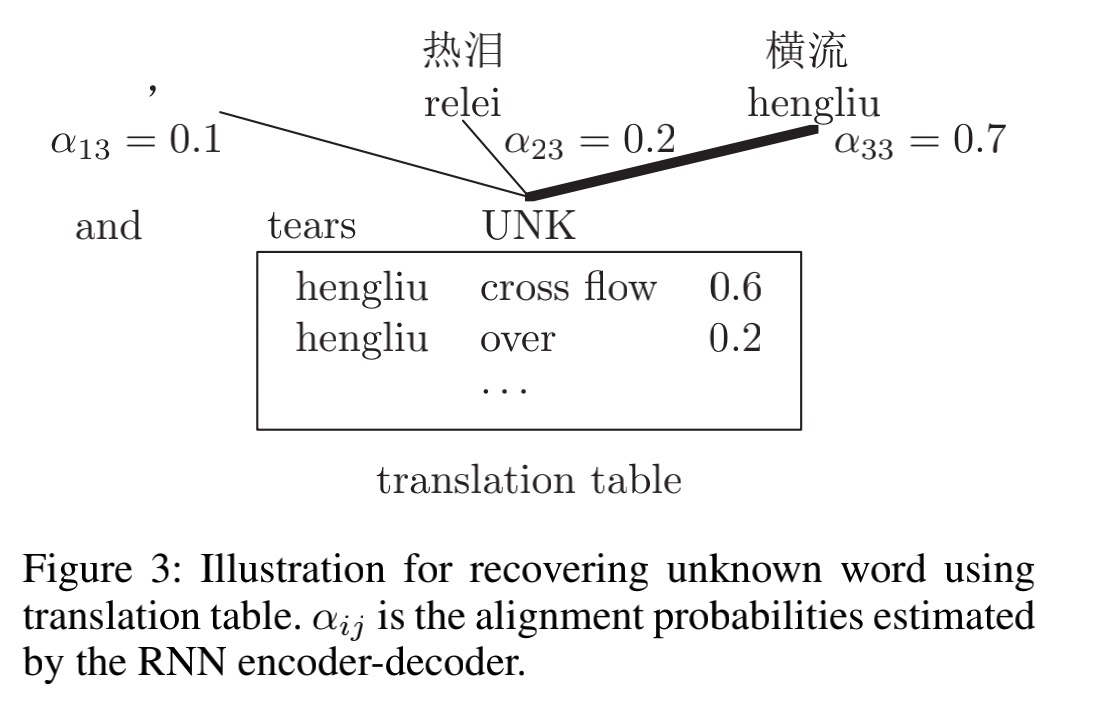
如图,其中$\alpha_{13},\alpha_{23}等$概率由RNN (注意力生成),对注意力最大的hengliu在翻译表中找到对应的最大概率的翻译。
Decoding
与一般NMT模型的decoding不同,在作者的解码器中,对每一个decode的单词,额外计算了单词翻译概率表中的单词翻译概率和语言模型评分和当前句子的长度。使用这些得分来获取更好的候选列表,log-linear model的参数更新使用MERT(minimum-error-rate-training),为了加速解码器,作者使用了优先队列选择对好的候选项去扩展。(和beam search一样)
Experiments
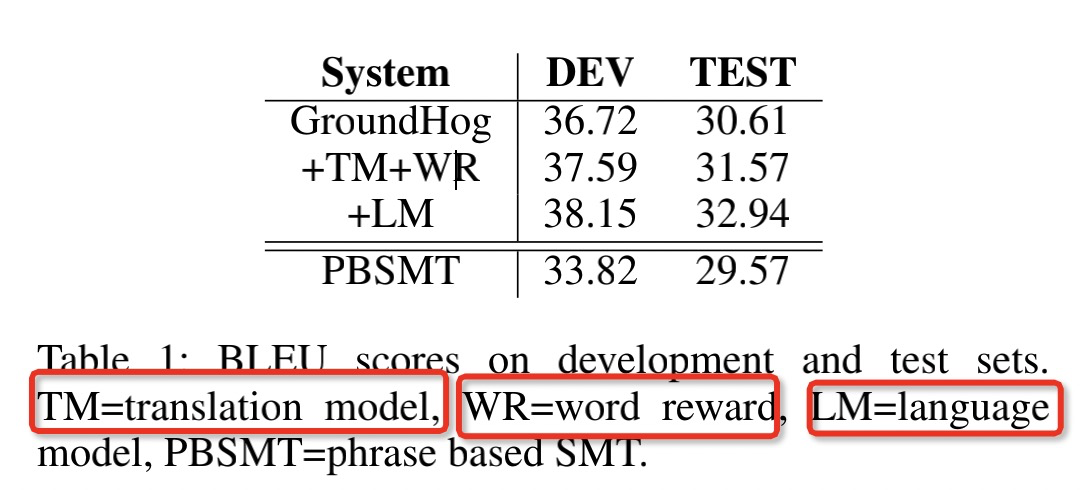
在单词翻译,OOV翻译,和候选列表三方面展示了作者的翻译系统

第二个图做了简单的消融,去掉单词翻译表之后,性能下降了。
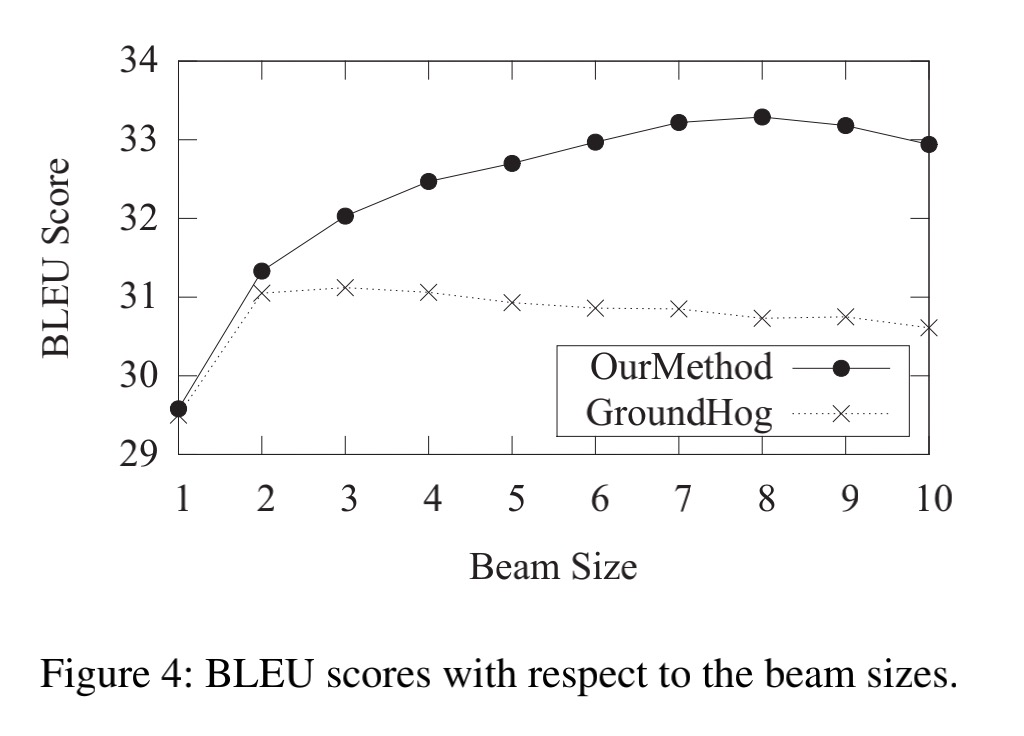
增大beam size,BLEU增加明显,说明使用更多的feature产生了更好的候选项。