- Published on
2018_ACL_迭代回译
Iterative Back-Translation for Neural Machine Translation 2018 ACL
迭代回译,实践中是简单的有效的。作者在高低资源下展示了迭代回译对翻译质量的提升。在 WMT 2017 German-English任务BLEU 上获得了已知最高的评分。
结论:迭代回译要使用好的模型进行回译。合成数据质量要高
单语数据利用相关工作
回译在2011年就有这个想法。最近相关的工作有对偶学习,作者使用对偶学习(NIPS 2016 微软提出https://www.msra.cn/zh-cn/news/features/dual-learning-20161207)的方式做了很多实验,但是并没有获得增益。
利用单语数据训练一个语言模型集成到翻译模型中,但是还没有证明效果可以超过back translation
模型回译质量的影响
作者直觉认为,好的回译系统可以产生好的合成双语数据,从而可以训练处好的翻译模型。所以作者以不同质量的翻译模型去验证这一直觉。
数据:使用2017 新闻领域 German-English数据,并且使用与双语数据等量的单语新闻领域数据(对领域单语数据进行下采样)。
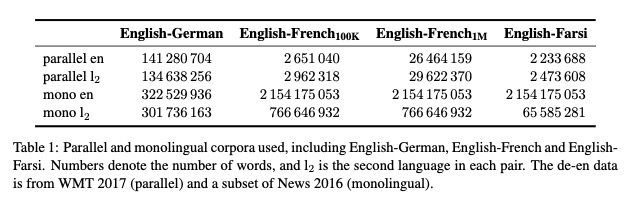
back translation模型:
- 10k iterations,0.15 epoch
- 100k iterations,1.5 epoch
- concergence,10 epoch
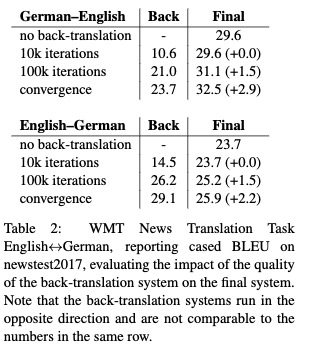
可以看到100k和convergence模型BLEU都获得了增加。可以看出回译系统的质量是影响翻译效果的重要因素。
迭代回译的步骤:

高资源数据实验
base翻译系统:shallow system,4-checkpoint ensembe, beam size 2
first back-translation system: 使用合成数据(+ base系统回译产生的数据),deep model, 8 checkpoint ensemble, beam size 2
final back-translation system:使用几个不同的系统shallow, deep,4 checkpoint ensembe
T
(模型使用的都是RNN Seq2seq架构)

可以看到,迭代回译的提升效果。
低资源数据实验
如图是在10万条数据双语数据上进行实验。English-French 翻译BLEU提升较高。但在Farsi-English上BLEU增加不明显。作者给出的原因是波斯语翻译比法语难,或训练数据中不同领域混合的结果(作者引出了一个新问题,迭代翻译数据和双语数据不同域的影响?)使用Moses短语翻译模型回译的效果在English-French上翻译较好(这个原因是不是需要分析一下?)。
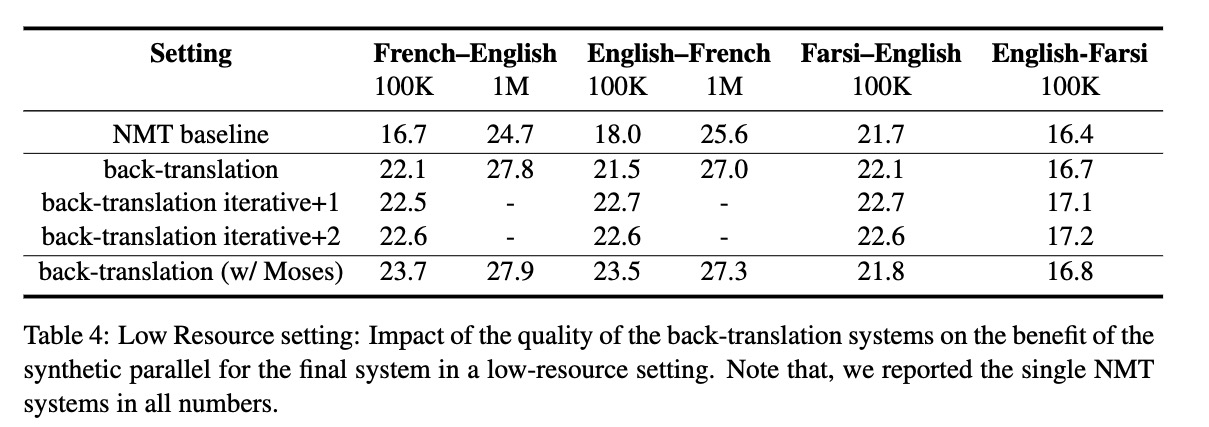
对真实和合成语料的比例进行了研究,发现更多的合成数据是有用的。(1:1 ,1:2 1:3)
单语数据的质量:回译很大程度上依赖反向翻译合成数据的质量。不同的语言对,不同的领域 迭代回译的效果可能是不同的。作者使用随机抽样的方法选择单语数据,因此句子抽到的次数可能不止一次。采用不同的抽样方法,可能带来不同的效果。