- Published on
机器翻译中域内小样本微调的正则
Regularization techniques for fine-tuning in neural machine translation 2017 ACL
在小数据上进行迁移学习(使用小规模领域内数据对通用机器模型进行微调)的一个问题是过拟合。作者测试了三种防止过拟合的方法(自己提出来了一种Tuneout),发现正则的技术可以使训练更加鲁棒,防止过拟合。实验结论在微调的时候使用dropout和MAP-L2组合会带来更稳定的训练,BLEU提升较为明显。
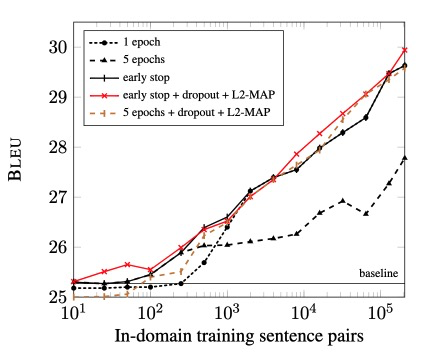
微调的领域数据和BLEU评分有对数关系...如下图
微调的其他方式还有使用域内数据在通用模型上继续训练。
机器翻译中,使用联合训练来解决域内数据稀少的问题。
正则化技术
Dropout
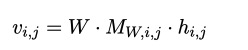
$M_{W,i,j}$ :bayesian dropout mask
MAP-L2
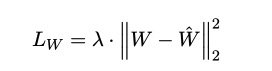
W是域内参数矩阵,W帽是固定的通用模型参数矩阵。
Tuneout
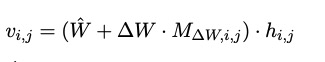
W冒:固定的域外模型参数
△W:参数变化矩阵
$M_{△W,i,j}$ :bayesian dropout mask
结果
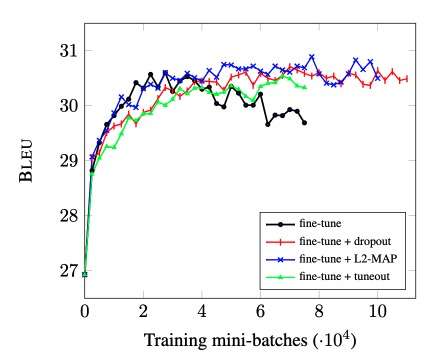
可以看到随着训练增多,单纯使用fine-tune的翻译能力下降。而正则化不然,是训练更加稳定
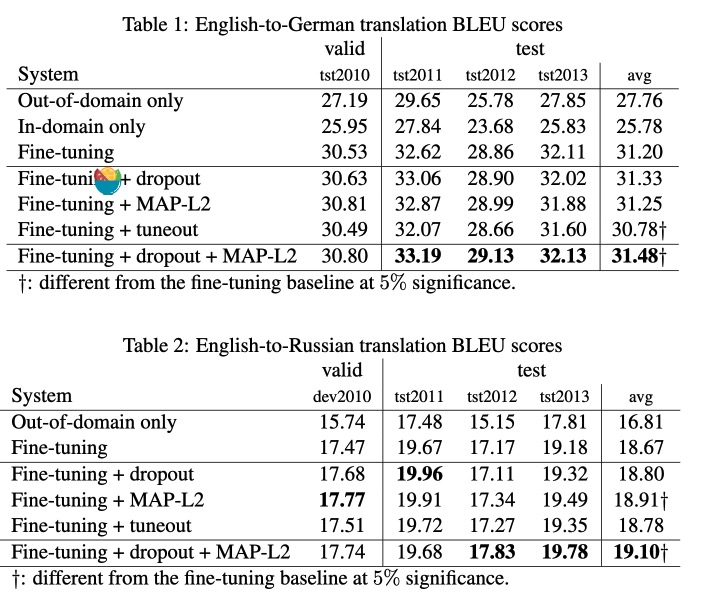
作者的方法并没有提升。dropout+MAP-L2的提升比较明显
作者在实验中使用了early stop,结尾说明对于少量的域内数据而言,有点不切实际,因为early-stopping需要依赖足够大的域内验证集。