- Published on
机器翻译模型架构记录
架构这东西,有意思也没意思。
除了之前的[The Best of Both Worlds: Combining Recent Advances in Neural Machine]
Google AI blog 2020: LSTM 作为decoder性能比Transformer decoder效果好
Massive Exploration of Neural Machine Translation Architures,提到small large embeddings matrix在梯度更新时候大致相同,也可能是large参数需要更好的优化方法,对于深度模型也是如此
decoder根据encoder最后输出进行初始化是有必要的。
双向LSTM比单向只好一点点。
注意力机制像一个weighted skip connection。注意力模型对decoder有较大梯度更新。
beam search:3 -10 LP 0.5 1.0差距不大
arxiv最新的一篇简单文章
ANALYZING ARCHITECTURES FOR NEURAL MACHINE TRANSLATION USING LOW COMPUTATIONAL RESOURCES
在100万数据集上训练
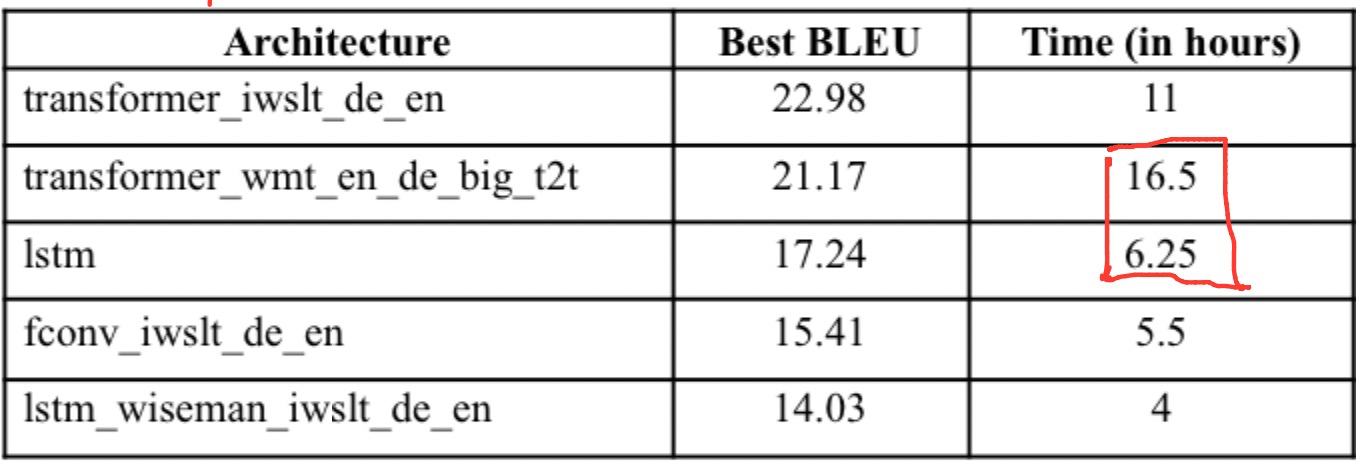
训练时间角度看,lstm快。(self attention ,feed forward encoder + lstm decoder)应该不错
BLEU上,base transformer效果好,big差一点,训练时间还更多。
除此之外,加宽 增大filter size到8192,15000。加深 :dlcl
但是效果不咋di,腾讯WMT21 用了很多Transformer变体,为了让生成结果多样性,然后对翻译结果做排序,可以看 WeChat Neural Machine Translation Systems for WMT21
多语言翻译:
21年的WMT似乎更喜欢用多语言翻译的模型。对低资源效果明显。