- Published on
计算机辅助翻译-coursera课程1-3
Computer aided translation CAT
为了了解行业的一些基础知识,常用工具等
翻译过程的论述
分析-转化-重构 翻译模式(转换生成语法)

释意理论
翻译不能直接进行语言符号的转化
而是 理解,脱离语言外壳, 表达
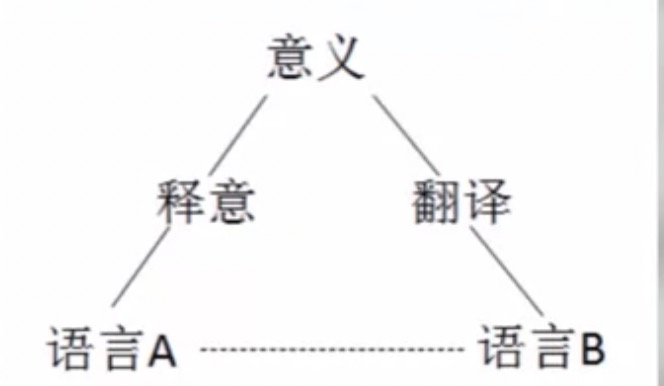
概括来说就是,理解原文,生成译文
译员翻译能力评估
西班牙巴塞罗那自治大学:PACTE(preocess in the Acquistion of Translation Competence and Evaluation) 译者的能力:双语交际能力,非语言能力(文化知识,主题知识,百科),专业操作能力,转换能力,心理生理因素,策略能力。
翻译问题分类
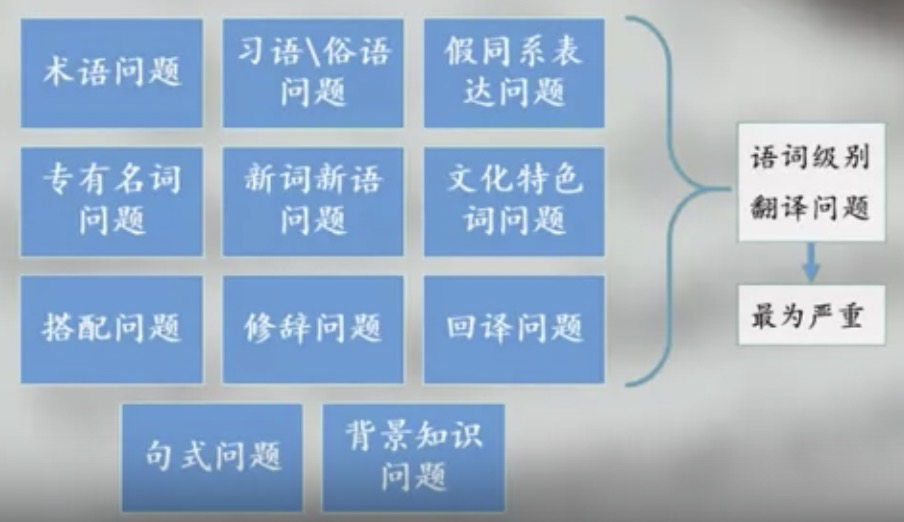
专业用语问题:解决辞典,语料库
(牙科医学领域翻译实践 filler只能翻译为充填剂,而不是填充剂)
俗语问题:
kick the bucket (一命呜呼)不等于 kick the barrel 踢桶
to bring down the house(满堂彩) 不等于 拆房子
解决:互联网,语料库,工具书
假同系表达
红茶 不等于 red tea
专有名词
人名,地名,机构名称,国家名称,奖项,仪器等等
解决:互联网,语料库(辞典容量小,更新慢)
新词:白富美....
文化特色词
邓小平理论,社会主义初级阶段等 一些有较深厚文化的词语。固定形式的
选词辨析

搭配
符合共现规律和习惯用法词
修辞
使文字更加生动形象。
回译
句式
分析清楚复杂句式的结构。如何通过变化,重塑目标句的句式结构
背景知识
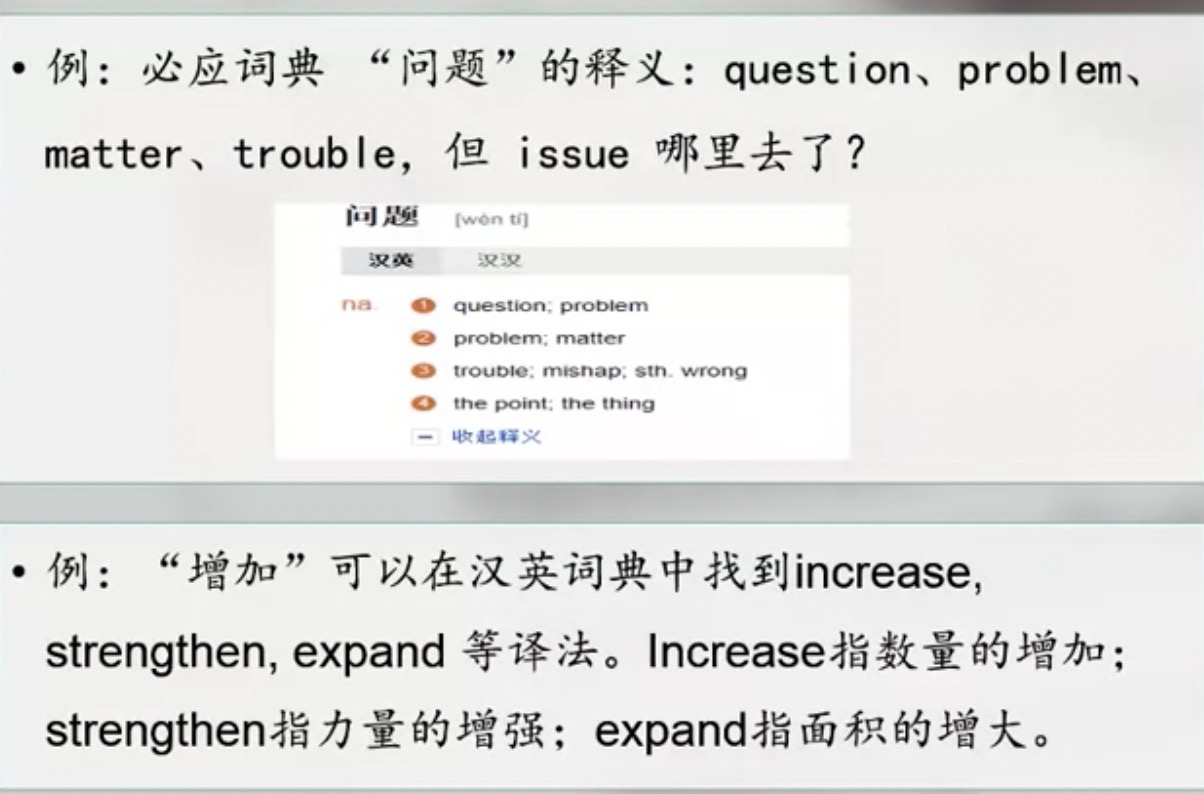
辞典问题
词条内部不足

英汉的汉语释义不能反过来找到原对应英语的表达方式

电子辞典也存在缺失问题
翻译技术组成
- 翻译过程的信息技术工具:电子词典,互联网信息资源,语料库
- 翻译技术的研究始于机器翻译
- 狭义CAT,翻译记忆 + 术语管理
- 广义CAT,一切辅助性工具,如QA
- 团队翻译的信息技术工具
- 翻译项目管理
- 翻译公司管理
辅助翻译的进化:
- 字典,网络版,wiki
- 翻译记忆 网络版
- 术语管理
- 自然语言处理技术
协同化的工作环境
- 翻译记忆交换
- 语言服务(翻译)过程管理
- 客户与翻译服务公司的互动关系
- 语言服务新模式
- Proz网站,译员之家
翻译质量评估
常说 信达雅
翻译质量是一个动态问题
常用工具
拼写检查,与罚检查,辅助翻译,机器翻译
好的译员:懂语言,文化,技术,管理
自动化翻译
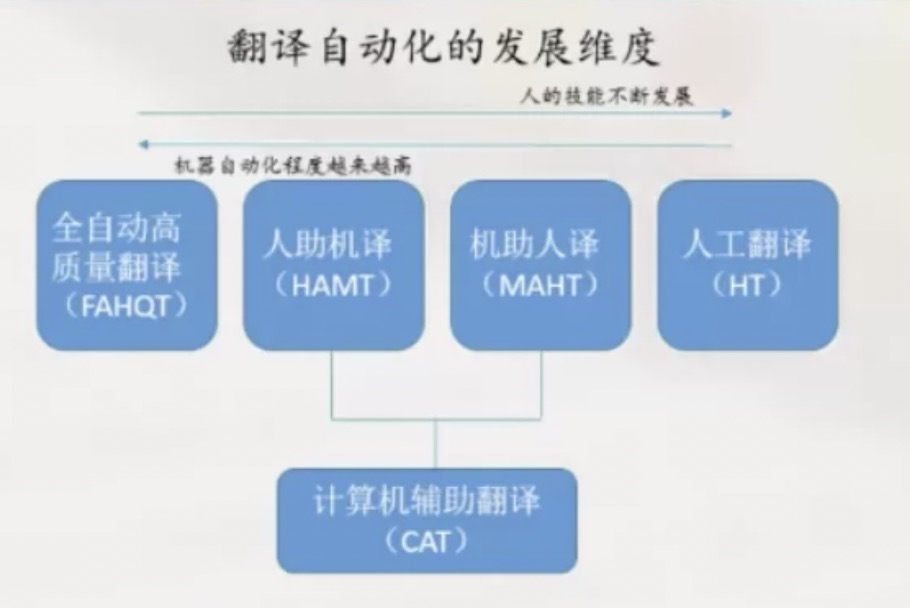
机助人译:OCR,语音识别,文件格式转换,翻译记忆+相关检索。对齐工具,术语库(一致性)。
商用计算机辅助翻译软件
SDL TRADOS,WORDFAST,DEJA VU,Alchemy Catalyst / Publisher
语料库
主要作用:检索(keyword in context KWIC)
建立语料库方法:
- 切分段落,句子,词汇 Segmentation
- 屈折语形态还原 Lemmatization
- 词性标注 POS tagging
- 句法分析 Parsing
- 双语对齐 Alignment
语料库:BNC,Linguateca,Sketch Engine,Europa.eu COCA
互联网搜索引擎/信息服务翻译实践
搜索引擎的分类
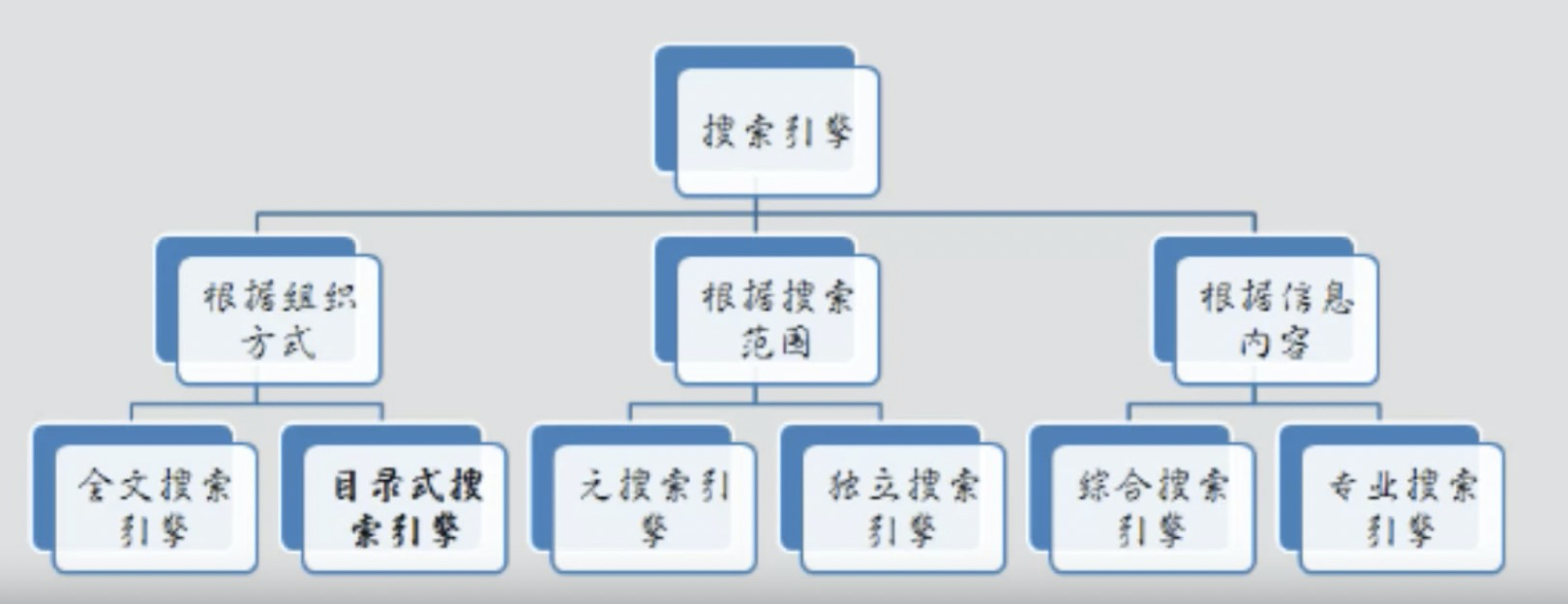
首先是目录式搜索引擎 YAHOO,(一级一级向下索引)
全文搜索引擎,altavista,Google,bing 百度,搜狗...
元搜索,对其他搜索引擎内容进行排序,
综合性搜索引擎:如google
基本工作原理
采集信息,索引,匹配,输出结果
爬取内容的处理:中文分词,英文词形,形态变化
结果排序(核心竞争)SEO搜索引擎优化,Google是goole page ranking,链接关系量化重要性。基础算法的改进:网站重要性,更新频率,内容分析。
使用规则
关键词(多角度),避免口语词汇(stop words)
逻辑检索符 与(+)默认方式 或(OR) 非( -) 减号前需要加入空格
加引号 完全匹配

filetype: 文件类型
define: geek 搜索geek的定义
link 链接到某个特征网址的网页。
related: 找到与该网页相似的网页
学术数据库 电子期刊数据库
- 中外文电子期刊数据库
英国Nature杂志 www.nature.com
还有很多专业的电子期刊网站
google scholar(泛 全)但是深入的找不到。一些专业的资料需要专业的搜索引擎来做。
知网,万方,weipu
开发获取的电子期刊:HighWire,DOAJ
- 电子图书与电子报纸
- 国内外科学信息门户
- 专利资源、科技报告、标准文献
电子书 电子报纸 Amazon,
CALIS,北京大学图书馆,
学术数据库一般流程
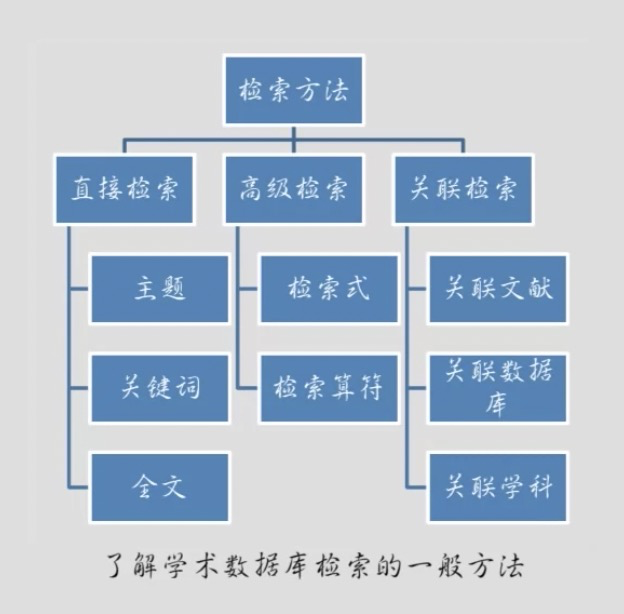
搜索引擎 诱导词
语料库与翻译研究
语料库产生背景
- 物质基础:电脑科技
- 思想基础:经验主义
(对现象有了积累之后,才能升华为理性。)
语料库定义:machine-readable(机器可读的),authentic(真实的),sampled(抽样),representative(代表性)
语料库建设
- Brown corpus 1970 100万词
- London-Lund Spoken Corpus 1960年代开始 1975年建成 2000小时谈话 广播
- COBULID Project 1980 词典编撰 2000万词
- Longman Corpus 1980年代 LLELC LSC LCLE 英语语料库目标是 编撰英语学习词典。
- British National Corpus (BNC)1991 1995 90% written + 10% spoken 对当代英国英文研究很好
- Xaira
- 美国国家语料库
国内早期语料库建设
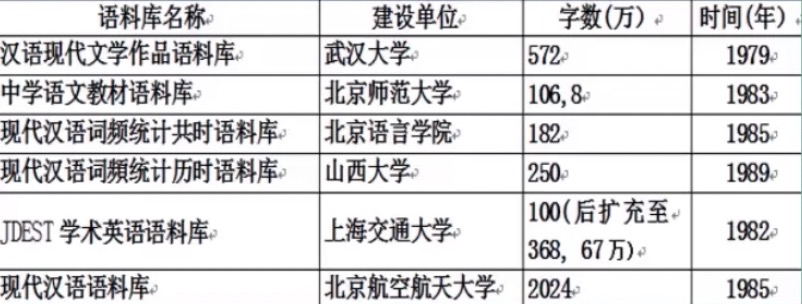
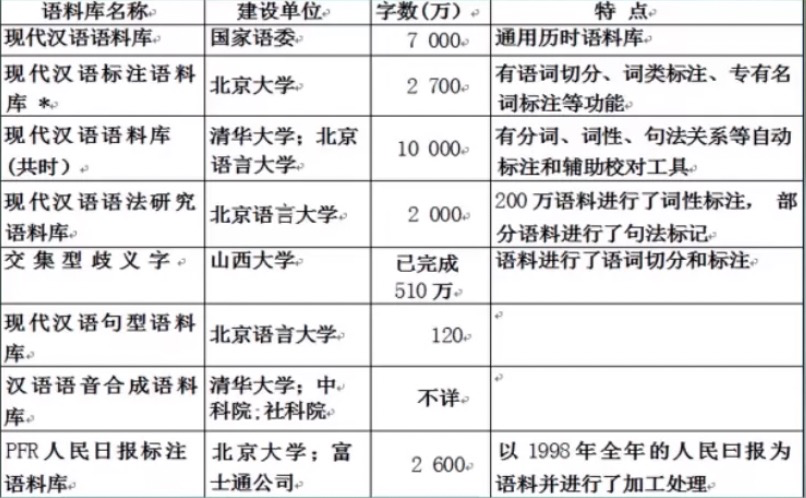
1998人民日报现在使用很广泛。
语料库特点
- 领域 vs 通用
- 平衡性
- 粗 细
- 加工深度 用途/成本/发展
问题:很少更新,自动化不高,缺乏语言资源管理。缺乏用户定制。成本大,周期长。高度分化,缺乏集成
现代语料库建设:wiki-based corpora Web-based corpora
1949年,美国数学家瓦伦 weifu Warren Weaver提出了统计机器翻译的基本思想
1993年,IBM提出 五种统计翻译模型
语言学范畴的语料库研究:
- 语法规则的发现和验证
- 语体、语言风格研究-(红楼梦究竟是不是一个人写的)
一个研究出现了问题,并不一定代表着这个方法有问题
多模态语料库 感觉挺不错
语料库支持的翻译研究和实践
应该注重翻译的结果还是 翻译的过程? 如何把语料库应用在翻译过程上,把语料库应用在理解原文和生成译文上。
可比语料库 - Comparable Corpus
Monolingual Corpus 单语语料库 外语单语语料库提供了分析观察语言的使用规则,借助语料检索和分析工具可能得到超过字典的效果。
语料库检索工具
- Wordsmith 商业
- Antconc,Paraconc
- CWB (开源 推荐)
- SPSS,Weka统计工具及数据分析工具 (商业,开源)
- 基于Web的语料库系统
- Sketch Engine 商业
- http://corpus.byu.edu
- http://ccl.pku.edu.cn