- Published on
Google-GNMT
Google’s Neural Machine Translation System: Bridging the Gapbetween Human and Machine Translation
Abstract
使用LSTM 8 encoder和decoder,残差连接,注意力连接
为了并行,较少训练时间,注意力在decoder底层和encoder顶层之间。
加速推理,使用了低精度。
使用wordpieces提高模型处理稀有词的能力
beam search使用了长度归一化和覆盖惩罚,coverage penalty 可以让 decoder 均匀地关注于输入序列 x 的每一个 token,防止一些 token 获得过多的 Attention
在使用强化学习在BLEU基础上改进模型时,发现BLEU的提高并没有提高人类评价效果。
在WMT14 English2French 和English2German,取得SOTA,人工评测中比短语翻译系统错误减少60%。
1 Introduction
NMT的缺陷:
- 训练和推理的时间
- 处理rare words,有方法指出可通过训练copy model,通过attention 机制来复制rare words,但这些方法在规模上都是不可靠的(对齐的质量因语言而异)。
- 翻译会漏译源句子中的单词,漏译。not cover input
3 Model Architecture
提到:encoder and decoder RNNs 需要足够的深才能捕获src和tgt语言中的细微不规则性,以提升准确率。即深层LSTM效果明显优于浅层LSTM。每增加一层LSTM就减少10%的困惑度
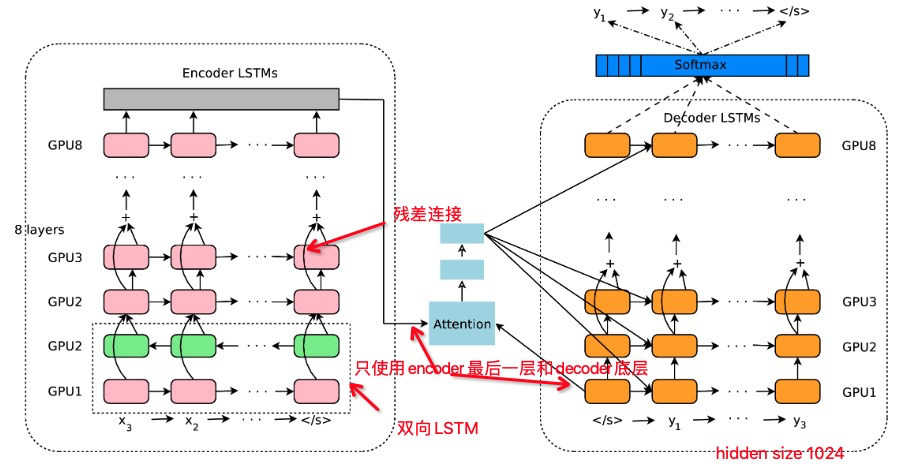
3.1 Residual Connections
简单堆叠LSTM 4层以下效果好,6层效果不佳,8层效果很差。
3.2 Bi-directional Encoder for First Layer
3.3 Model Parallelism
4. Segmentation Approaches
开放词表问题。一种解决办法是复制机制,或者基于attention,对齐模型,point network
另一种是subword,比如 chararacters,mixed word/characters 或者 wordpiece算法
4.1 Wordpiece Model
给定数据和词表大小,生成词表。
使用8k到32k的总词汇量都取得了较好的准确率和较快的解码速度
共享词表模型,来让MT模型有从源端的复制能力
4.2 Mixed Word/character Model
将source或target中OOV的单词 转换为 special tokens。
如Miki 转换为 <B>M <M>i <M>k <E>i
5. Training Criteria
使用极大似然训练,模型在训练期间没有观察到不正确的输出。所以模型解码过程中不会有较好的鲁棒性。
在大数据上训练的MT model,使用任务奖励依旧能够提高模型
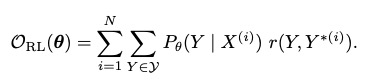
函数是单句话的score,BLEU在单句表现不好,它是一个语料库的衡量标准。
这里使用GLEU,将句子切分为 1,2,3,4 元组,计算min(召回率和精确率)
线性组合ML,和RL的目标函数如下:
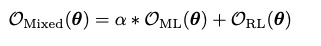
先使用ML进行训练直到收敛。然后使用组合函数进行训练,直到BLEU值不提高。
$\alpha$通常设置为0.017
6. Quantizable Model and Quantized Inference
增速
7. Decoder
beam search 增加了 长度归一化 和 覆盖惩罚。
beam search倾向较短的结果,并且在decoder中需要比较长度不同的句子。所以需要使用长度归一化
覆盖机制coverage penalty,使注意力模块完全覆盖源句。
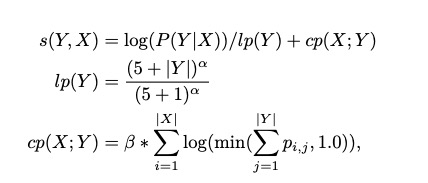
$p_{ij}$使第j个target word在第i个source word上的概率。
BLEU对BLEU评分而言
$\alpha=0.2,\beta=0.2$可以将原始BLEU评分增加1.1
RL之后的MT模型在优化后的beam search上BLEU没有提升
8. Experiments and Results
隐层 1024
8.1 Datasets
En->De:5M数据
En->Fr:36M
newstest2014测试集
8.2 Evaluation Metrics
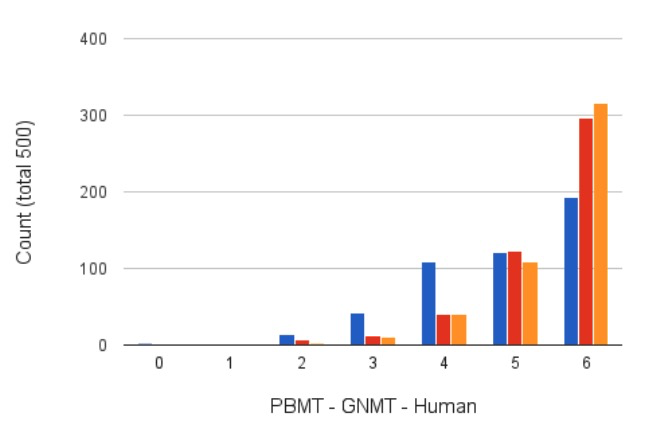
6 代表完美
4 可能有一些语法错误
2 遗漏了重要部分
0 完全无意义的翻译
8.3 Training Procedure
参数初始化 uniformly [-0.04 0.04]
梯度裁剪 5.0
优化器测试:
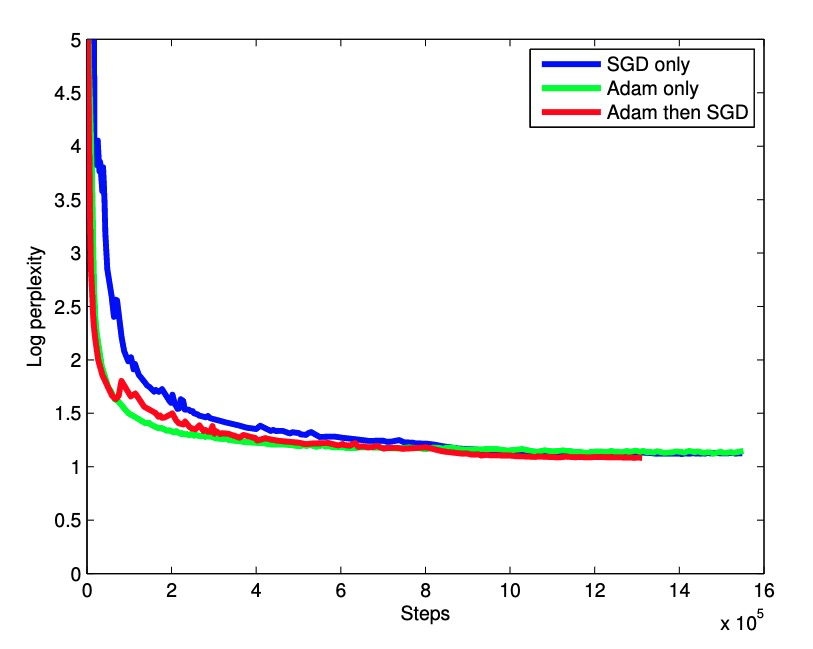
Evaluation after Maximum Likelihood Training
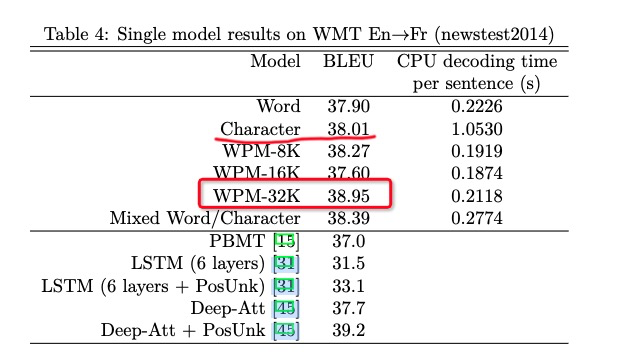
character表现得很接近最好的,但是输入输出序列过长。
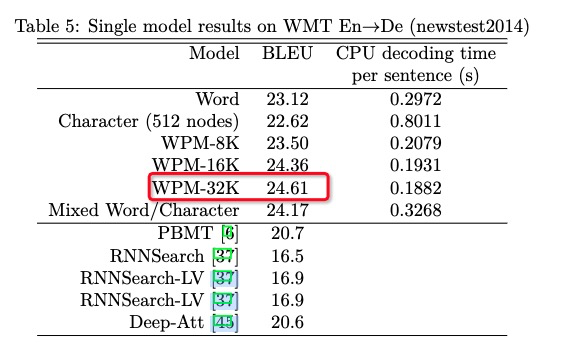
En-Fr数据36M,En-De 5M,BLEU差距很大。所以数据很关键
8.5 Evaliation of RL-refined Models

这里 beam search 算法的优化和RL的微调存在重叠。
否则BLEU提升应该会多1个点。
8.6 Model Ensemble and Human Evaluation
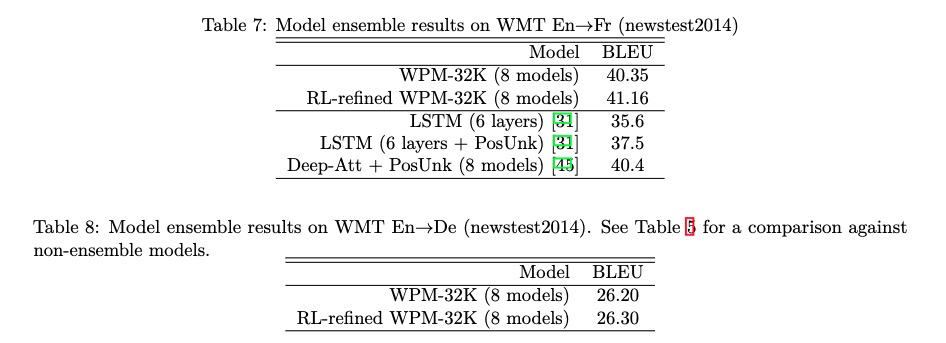
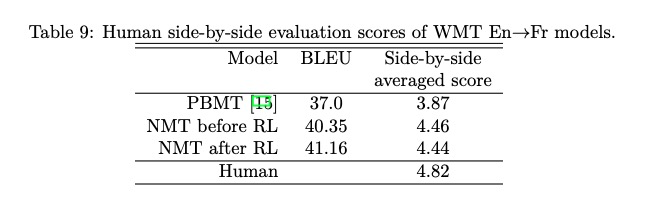
RL虽然能提高BLEU评分,但是人工评价没有提升。BLEU或许和人工评测不匹配。
8.7 Results on Production Data
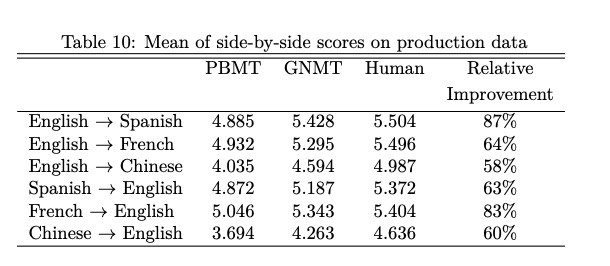
模型减少了60%以上的翻译错误