- Published on
笔记-Dynamic_Terminology_Integration_for_COVID-19_and_other_EmergingDomains
Dynamic Terminology Integration for COVID-19 and other EmergingDomains
WMT2021 Shared TASK : Machine Translation using Terminologies
对于目前的新型冠状病毒这样新兴或其他小领域来说,没有特定的,较多的领域平行语料。所以作者提出了动态术语集成,在不干扰训练过程情况下,提高术语的准确率。在测试集实现了94% COVID-19的术语准确率。
2. Methods
2.1 术语过滤
术语翻译需要正确和一致,通常是翻译学家或者领域专家整理。在一般的平行语料中存在各种各样的术语翻译形式(全写,缩写,简写等)
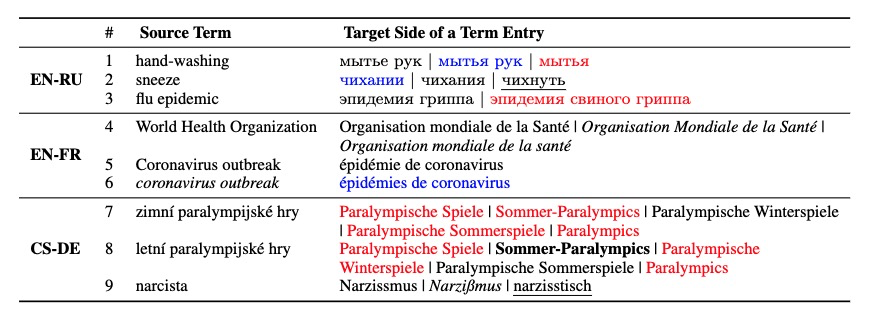
词尾变化为蓝色,错误翻译是红色,拼写变体为斜体,加粗是其他可能的翻译,其他术语是下划线。(并且也有有些原术语本身词尾就发生了变化。)
- 过滤不属于术语的表达形式(比如一句话,完整的子句,公式,由术语组成的表达式,缩写词,下表1-6and8)
- 丢弃源语言和目标语言相同具有表示,但一方表示不完整的术语,如下表7,9
- 使用IDF过滤出非general得词语
除了过滤之外,对于WMT任务来说,还需要从多个候选翻译中选择一个,作者使用了两个策略:
- 直接选第一个候选
- 但是术语质量是不同的,作者又通过对齐的方法来测试。Alignment-based对齐工具:https://github.com/robertostling/eflomal
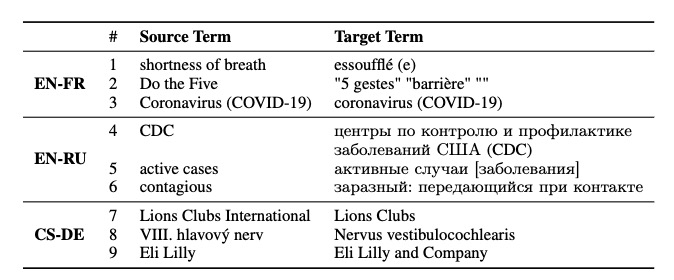
如下,有些候选翻译质量相同(1,3,6,7),候选翻译过长(6,8),不足(4),对齐的这种方式主要还是给予字典的方式,而没有考虑词尾变化。(2)
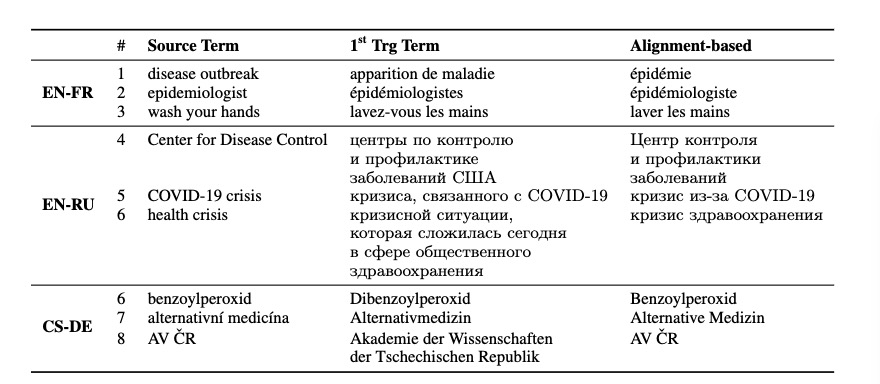
2.2 术语识别
因为语言形态学的原因使得英等语言的术语识别比较麻烦,作者这里只使用词干提取(没有使用形态标记,原因说词干提取速度较快,并且对低资源的覆盖率更广),还需要做的是源语言进行词义消歧的判断,但是此作者没有使用(词义消歧需要大规模平行语料训练。)
2.3 集成术语约束
考虑目标语言的词法复杂性,这里使用Facilitating terminology translation with target lemma annotations该工作,使用TLA(target lemma annotation)来增强数据
如:infections|s инфекция|tresult|w in|w mild|w symptoms|w
|s 代指token是否是源语言
|t 目标语言字典形式(lemma)术语, 我的理解是通过这个标记来提供目标形态句法上下文。
|w 普通的源语言词汇
依照这样的方式,传递软术语约束
Result
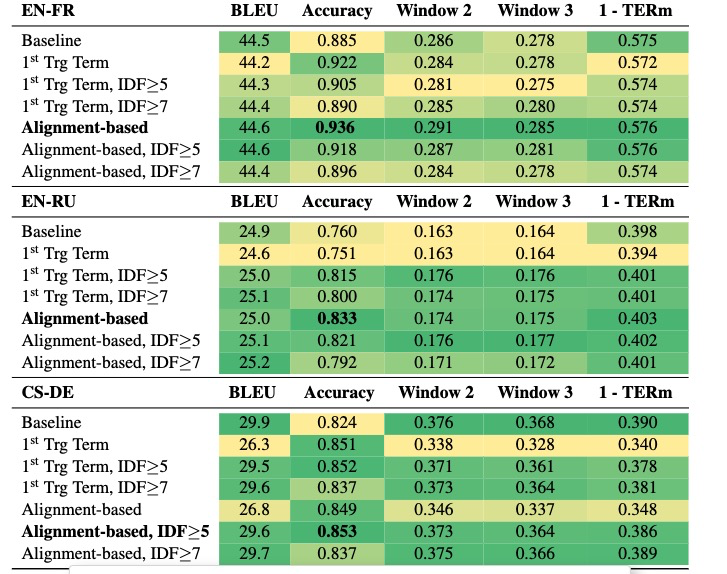
作者提出的观点:
- 术语改善的操作对测试数据BLEU大小影响不大,会导致术语翻译方面的研究不被重视
- 用语改进的MT的术语集必须具有更高的质量