- Published on
笔记-Learning_Kernel-Smoothed_Machine_Translation_with_RetrievedExamples
在线更新已部署的模型。learnable kernel和mixing weight
提高1.1,1.5 BLEU
1 Introduction
Nearest Neighbor Machine Translation 使用k-nearest-neighbour在token级别检索提高MT。
句子级检索不容易找到和测试实例足够相似的实例,这会带来噪音。并且完全的非参数容易对检索到的实例过拟合。尽管KNN-MT提高了领域的翻译能力,但是泛化能力不行。
作者提出了一个可学习的kernel动态的计算当前上下文检索实例的相关性。
然后将实例的权重和模型产生的分布自适应混合权重进行下一个单词预测。
为了让KSTER稳定,作者提出了retrieval dropout strategy。(训练的时候可以检索到相似样本,但在测试inference阶段不同。)
2 Related Word
Domain Adaptation for MT
微调,有个灾难性遗忘问题。(也有一些微调技巧的文章,blog中有),除此之外,还有一些稀疏性领域适应方法,比如只更新部分参数。
Online Adaptation of MT by Non-parametricRetrieval
Non-Parametric Adaptation for Neural Machine Translation 基于句子n-gram相似度检索
token level KNN-MT
实例相似性检索都是基于模糊匹配,或embeding 相似度 或二者混合
3 Methodology
3.1 Kernel-Smoothed Machine Translation
Base Model for Neural Machine Translation
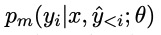
Kernel Smoothing with Retrieved Examples
作者对检索的相似样本构建database,由训练数据中所有token level的数据以key-value pairs组成。
k:模型decoder中一层的中间表示
v:对应的ground truth 目标token
k可以看做为v的上下文表示,通过模型decoding来获得k,v
在decoding过程中,我们计算$q_i=f_{NMT}(x,\hat{y}_{<i};\theta)$和k的$L^2$距离$d_j$,每一个检索的样本可以表示一个三元组$({k_j,v_j,d_j})$
使用检索的样本计算出如下概率:
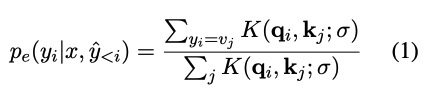
K就是kernem function $\sigma$是kernel的参数。
然后将这两个概率分布加权,$\lambda$的计算在下面3.3
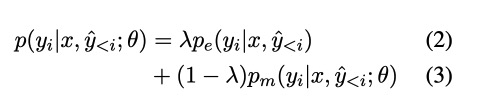
3.2 Learnable Kernel Function
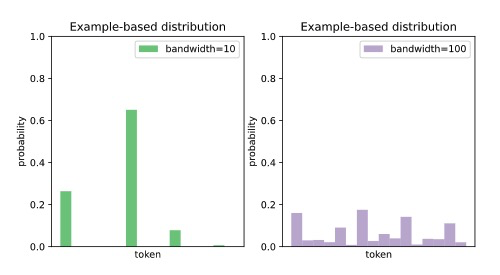
作者使用Gaussian kernel 和Laplacian kernel
使用了一个network来估计bandwidth
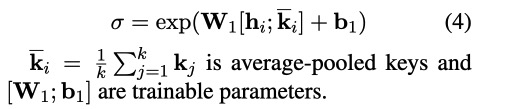
3.3 Adaptive Mixing of Base Prediction andRetrieved Examples
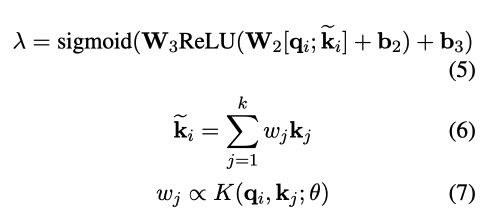
Knn-MT可以被看做拥有固定的高斯核和权重的KSTER。
3.4 Training
cross entropy loss between the mixed distribution and ground truth target tokens
3.5 Retrieval Dropout
检索k+1个相似样本,然后丢掉最相似的。
4 Experiments
4.1 Datasets and Implementation Details
WMT14 En-De De-En 4.5M训练数据 和 newtest2013验证集 newstest2014测试数据

实施细节:
BPE 30k,共享词表
Transformer最后一个docker block,feed forward的输出用来构建databases和query。
# decoder流程
stl_x = None
for layer in self.layers:
stl_x = x
x = layer(x=x, memory=encoder_output,
src_mask=src_mask, trg_mask=trg_mask)
#
c = self.layers[-1].context_representations(stl_x,
memory=encoder_output, src_mask=src_mask, trg_mask=trg_mask)
# 调用的函数
def context_representations(self, x: Tensor = None,
memory: Tensor = None,
src_mask: Tensor = None,
trg_mask: Tensor = None) -> Tensor:
# decoder/target self-attention
x_norm = self.x_layer_norm(x)
h1 = self.trg_trg_att(x_norm, x_norm, x_norm, mask=trg_mask)
h1 = self.dropout(h1) + x
# source-target attention
h1_norm = self.dec_layer_norm(h1)
h2 = self.src_trg_att(memory, memory, h1_norm, mask=src_mask)
# final position-wise feed-forward layer
o = self.feed_forward.layer_norm(self.dropout(h2) + h1)
return o
使用FAISS做最近邻检索。采用倒排和product quantization来加快检索速度。
以fp16存储降低内容使用。
设置参数k=16来平衡翻译质量和推理速度。
base model 训练了 20万步,5 checkpoints avg,KSTER 30k steps。
batch size 32768
learning rate 0.0002
新增52.6万参数
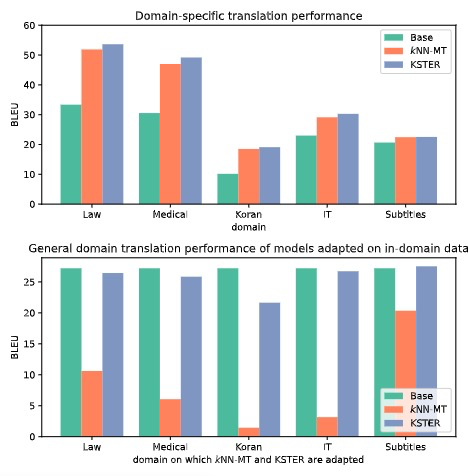
4.2 Domain Adaptation for MachineTranslation
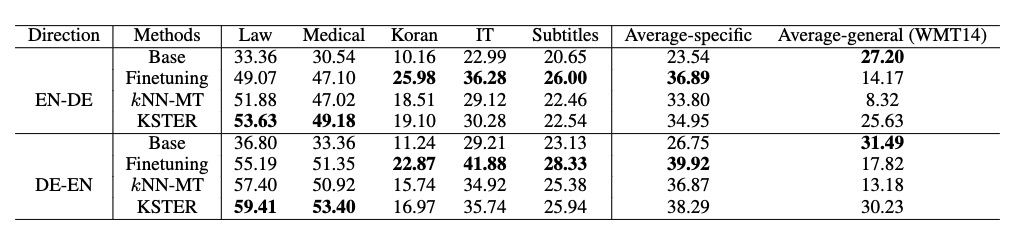
Finetuning在domain数据下,效果最好,但是general性能不好。
鲁棒性测试:
使用EDA造噪音数据。
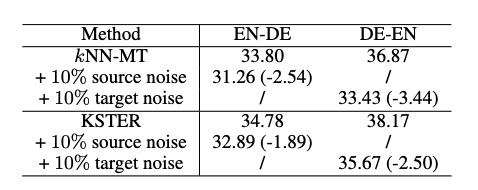
目标端噪音比源端噪音对翻译性能的负面影响更大。
4.3 Multi-Domain Machine Translation
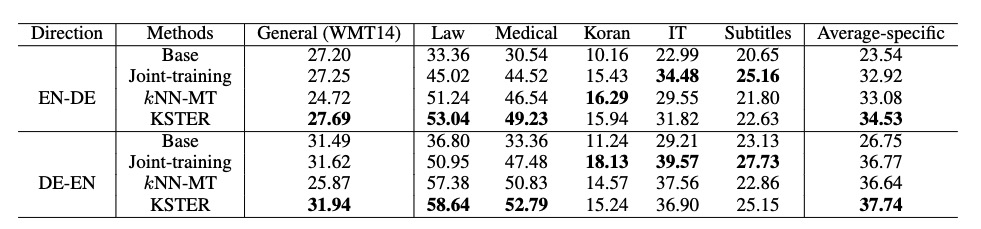
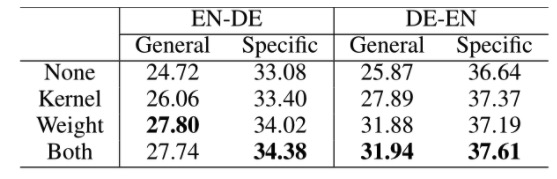
General-specific domain performance trade-off
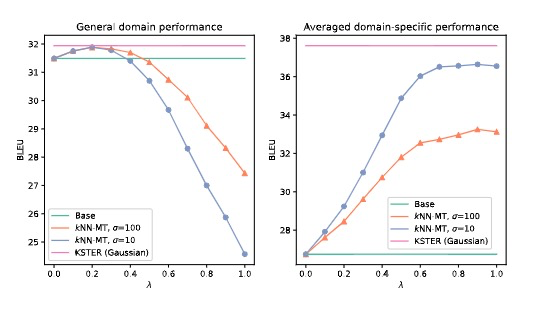
当系统预测更多地依赖于搜索的例子(低带宽和高混合权重)时,KNN-MT在特定领域内的翻译性能更好,相反,当系统预测更多地依赖于NMT预测(高带宽和低混合权重)时,可以获得更好的通用域翻译性能。
KSTER采用自适应核和混合权重在一般领域和特定领域都取得了更好的性能。
如下,领域之间有不同的权重和bandwidth。
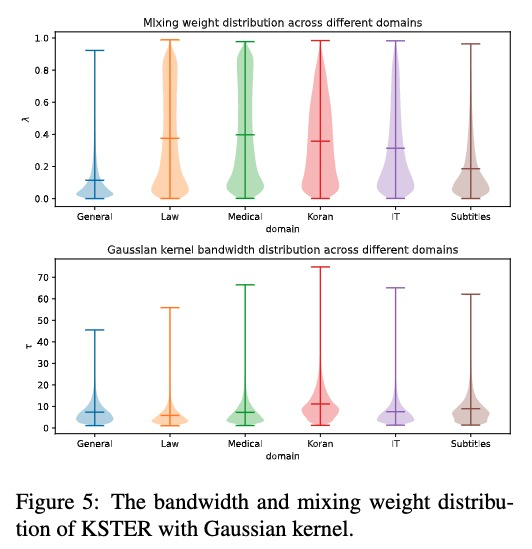
未见领域的泛化能力,KKSTER要好
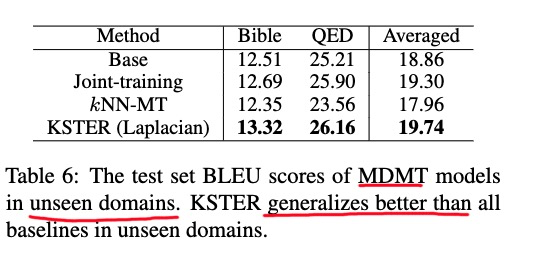
4.4 推理速度
1.19 倍 base model
5 分析
5.1 Ablation Studies of Proposed Methods
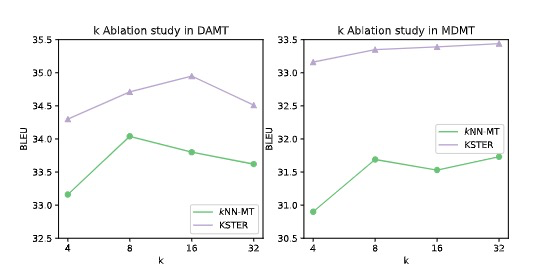
learnable kernel和mixing weight 都会带来提升。
KSTER outperforms kNN-MT with all k selections
Retrieval dropout improves generalization
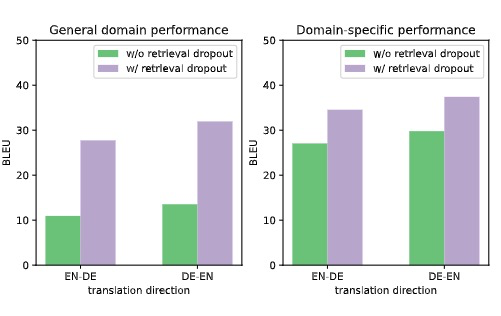
5.2 对翻译的细粒度影响
Kernel-smoothing influences verbs, adverbsand nouns most
通过单词是否有模型生成来确定kernel-smoothing的影响
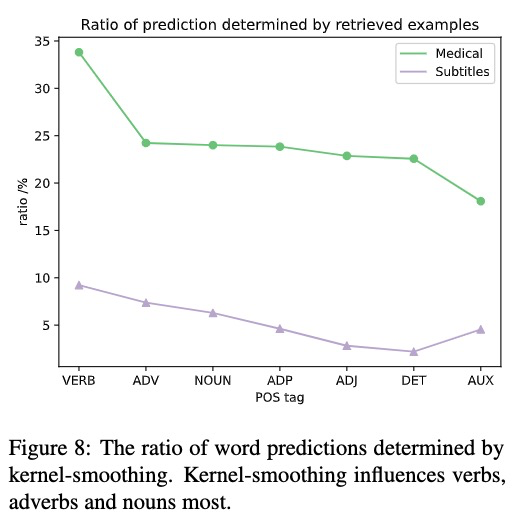
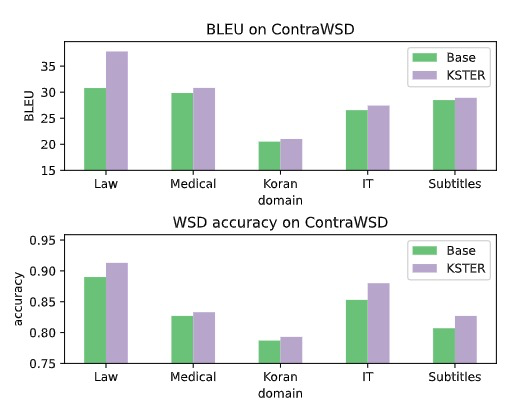
核平滑有助于词义消歧
使用ContraWSD,通过sentence embedding选择300个与领域数据最相似的作测试。
论文复现结果
en-de翻译 Koran领域
inference no combiner: koran test 10.16 (原始值 10.16)
index token_map embeddings.npy 根据 Koran de生成
inference with staic combiner :koran test 18.70 (原始值 18.51)
inference with dynamic :laplactian 18.87 gaussian 18.87 (原始值:19.10)自己训练的best ckpt:18.42