- Published on
低资源领域适应MT
https://blog.machinetranslation.io/nmt-domain-adaptation/
如何使用丰富的双语资源(通用)去训练低资源(领域内)的MT模型?
Incremental Training/Re-training/Continue training: 在资源丰富的语料上预训练,然后继续在低资源数据上继续训练。
Ensemble Decoding(of two models):平均两个模型的解码预测概率矩阵。
Combining Training Data:合并 高低资源的数据训练一个模型。
Data Weighting:给低资源语料在训练过程中更大的权重。
1. Incremental Training
使用预训练模型在低资源数据上继续训练,会造成灾难遗忘(“catastrophic forgetting“),通常会在继续训练过程中组合域内通用数据。
也有一种想法是在域内数据上训练学习新词汇(术语),增加词汇表。可以使用Opennmt的update_vocab参数来做。更改基础模型的单词词汇表外,同时保持共享单词的权重。
2. Ensemble Decoding(2 models)
Fast Domain Adaptation for Neural Machine Translation
两个模型分别是,预训练模型 和 在低资源上对预训练模型继续训练模型
需要主要,这两个模型的词表文件需要相同。预处理生成词表过程中,需要同时包含通用和域内数据。
3. Combining Training Data
通用领域内语料库合并,根据词频率生成词典时,会造成领域内术语因频率低而在词表中缺失。
对于MT中增加领域内数据的方法:
使用fast align,eflormal等对齐工具,生成领域内数据的对齐
0-0 1-1 2-2 2-3 3-4
然后根据对齐,提取n-gram片段,作为新的领域数据。最后做一些重复过滤,删除过长的句子等操作。
如上这种方法,对于少量数据还是有点效果,在某些片段上得到更好的翻译。如果对于所用数据使用次方法,总体翻译质量会变差。
4. Data Weighting
对领域内和通用数据指定抽取权重。让模型在训练过程中”见“过更多次领域内数据
4.1 Mixed Fine-Tuning
An Empirical Comparison of Domain Adaptation Methods forNeural Machine Translation
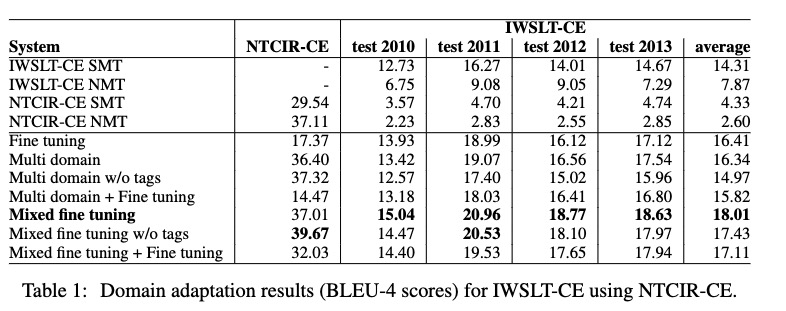
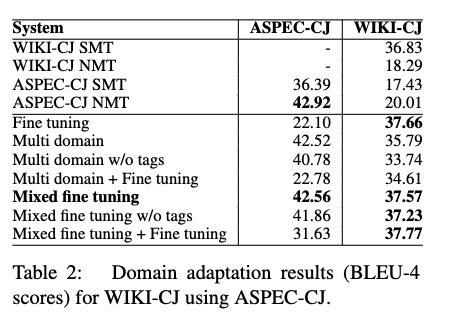
通用 领域数据 抽取比例 1:10
对域内数据做过采样。
- 方法在域内数据在50k到500k时比较有效。对于更多的域内数据,可能需要调节权重。
- 如果baseline的数据太大,可以从通用数据中随机抽取10倍域内数据
- 使用领域内和通用数据构建词表文件
- finetuning过程中,dev、validation 数据从领域内数据中抽取
- finetuning后,采用通用 和 领域内的测试集对模型进行测试。
中英方向,NTCIR专利领域数据。IWSLT TED talks数据
中日方向,ASPEC科学领域数据,Wiki data,
在领域数据少的时候,SMT的效果较好。