- Published on
笔记-nanoGPT
GPTConfig
block_size: 1024 输入序列的最大长度
vocab_size: 50257 词表大小
n_layer: 12
n_head: 12
n_embd: 768
dropout: 0.1
CausalSelfAttention
多头自注意力机制。
多头,输入e_embd 768维的向量,切分12分,一个头是64维。
B: batch size
T: sequence length
C: embedding dimension
输入:x [B,T,C]
q,k,v [B,T,C] 进过c_attn Linear映射切分为q,k,v矩阵
q: [B, n_head, T, C/n_head]
k: [B, n_head, T, C/n_head]
v: [B, n_head, T, C/n_head] 将去q,k,v矩阵view
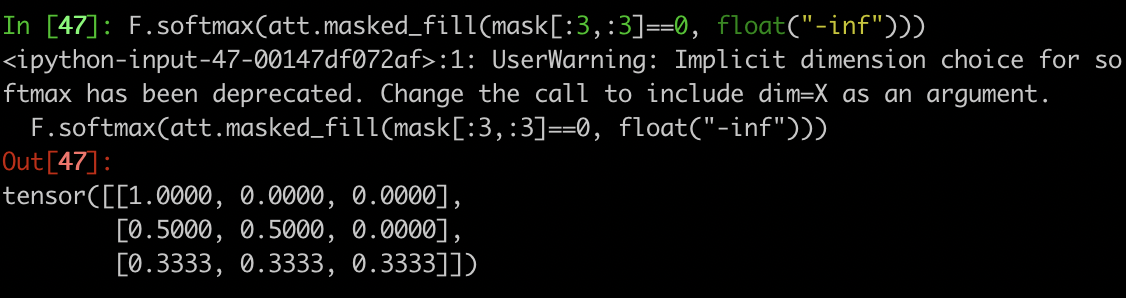
> self attention softmax(mask(scale(matmul(q,k))))
matmul 矩阵相乘: [B, n_head, T, C/n_head] x [B, n_head, C/n_head, T] = [B, n_head, T, T] 得到一个注意力矩阵。
scale: 除以 一个常量
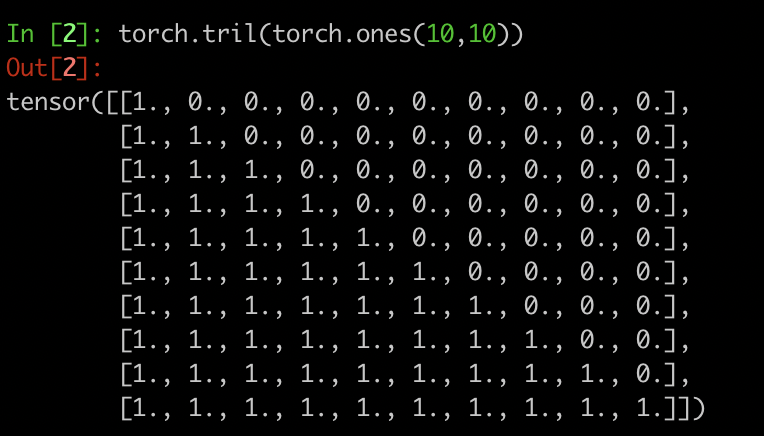
mask: 注意力矩阵代表每个单词和其他所有单词的相关性。GPT文本生成只需要关注,当前位置之前的单词序列,所以要将之后位置的单词遮蔽掉。(对)
softmax:当前词和历史单词的相关程度。
matmul v: [B, n_head, T, T] x [B, nh, T, hs] = [B, nh, T, hs]
view :[B,T,C] 与输入 维度相同。
输出:[B,T,C]
class CausalSelfAttention(nn.Module):
"""
自注意机制
"""
def __init__(self, config):
super().__init__()
assert config.n_embd % config.n_head == 0
# key, query, value projections for all heads, but in a batch
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd)
# output projection
self.c_proj = nn.Linear(config.n_embd, config.n_embd)
# regularization
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
# causal mask to ensure that attention is only applied to the left in the input sequence
# 下三角矩阵
self.register_buffer("bias", torch.tril(torch.ones(config.block_size, config.block_size))
.view(1, 1, config.block_size, config.block_size))
self.n_head = config.n_head
self.n_embd = config.n_embd
def forward(self, x):
B, T, C = x.size() # batch size, sequence length, embedding dimensionality (n_embd)
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
q, k, v = self.c_attn(x).split(self.n_embd, dim=2)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
# causal self-attention; Self-attend: (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
att = att.masked_fill(self.bias[:, :, :T, :T] == 0, float('-inf'))
att = F.softmax(att, dim=-1)
att = self.attn_dropout(att)
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side
# output projection
y = self.resid_dropout(self.c_proj(y))
return y
MLP
feed forward
输入x: [B, T, C]
fc: 线性层将x维度变为 [B,T,C*4]
Gleu
Proj: 线性层还原x维度为 [B,T,C]
输出:[B,T,C]
class MLP(nn.Module):
def __init__(self, config):
super().__init__()
self.c_fc = nn.Linear(config.n_embd, 4 * config.n_embd)
self.c_proj = nn.Linear(4 * config.n_embd, config.n_embd)
self.dropout = nn.Dropout(config.dropout)
def forward(self, x):
x = self.c_fc(x)
x = new_gelu(x)
x = self.c_proj(x)
x = self.dropout(x)
return x
new_gelu图像
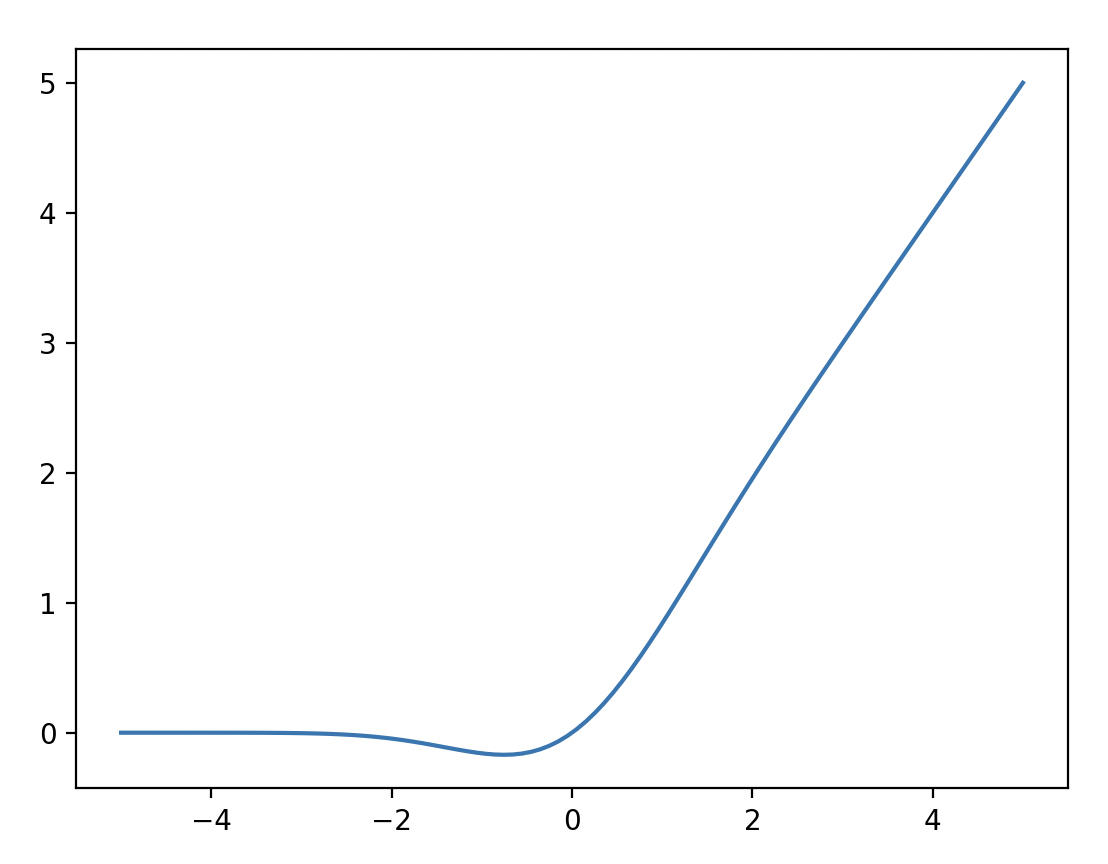
# 绘制代码
import torch
import math
import numpy as np
import matplotlib.pyplot as plt
def new_gelu(x):
return 0.5 * x * (1.0 + torch.tanh(math.sqrt(2.0 / math.pi) * (x + 0.044715 * torch.pow(x, 3.0))))
x = np.linspace(-5, 5, 100)
y = []
for i in x:
y.append(new_gelu(torch.tensor(i)).item())
x = list(x)
plt.plot(x, y)
plt.show()
Block
流程layernorm(x) -> attn -> layernorm -> mlp
class Block(nn.Module):
def __init__(self, config):
super().__init__()
self.ln_1 = nn.LayerNorm(config.n_embd)
self.attn = CausalSelfAttention(config)
self.ln_2 = nn.LayerNorm(config.n_embd)
self.mlp = MLP(config)
def forward(self, x):
x = x + self.attn(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x
GPT
wte: word embedding [vocab_size, n_embd]
wpe: position embedding [block_size, n_embd]
lm_head: [n_embed, vocab_size]
lm_head 和 wte做了一个参数共享。
class GPT(nn.Module):
def __init__(self, config):
super().__init__()
assert config.vocab_size is not None
assert config.block_size is not None
self.config = config
self.transformer = nn.ModuleDict(dict(
wte=nn.Embedding(config.vocab_size, config.n_embd),
wpe=nn.Embedding(config.block_size, config.n_embd),
drop=nn.Dropout(config.dropout),
h=nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
ln_f=nn.LayerNorm(config.n_embd),
))
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
self.transformer.wte.weight = self.lm_head.weight
# report number of parameters
n_params = sum(p.numel() for p in self.parameters())
print("number of parameters: %.2fM" % (n_params / 1e6,))
forward函数,
Idx输入:[B,T]
计算
- pos位置矩阵:[1,T]
- tok embeding: [B,T,C]
- pos embedding: [B,T,C]
- 位置编码和token编码相加 输入到n_layer的block中,得到 [B,T,C]矩阵
如果有target则计算loss,没有只返回序列最后的logits
lm_head: 得到 [B,T,vocab_size]
loss计算
def forward(self, idx, targets=None):
device = idx.device
b, t = idx.size()
assert t <= self.config.block_size, f"Cannot forward sequence of length {t}, block size is only {self.config.block_size}"
pos = torch.arange(0, t, dtype=torch.long, device=device).unsqueeze(0) # shape (1, t)
# forward the GPT model itself
tok_emb = self.transformer.wte(idx) # token embeddings of shape (b, t, n_embd)
pos_emb = self.transformer.wpe(pos) # position embeddings of shape (1, t, n_embd)
x = self.transformer.drop(tok_emb + pos_emb)
for block in self.transformer.h:
x = block(x)
x = self.transformer.ln_f(x)
if targets is not None:
# if we are given some desired targets also calculate the loss
logits = self.lm_head(x)
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
else:
# inference-time mini-optimization: only forward the lm_head on the very last position
logits = self.lm_head(x[:, [-1], :]) # note: using list [-1] to preserve the time dim
loss = None
return logits, loss
generate
输入 idx [B,T]
返回 [B,T] 新增加模型预测的token
def generate(self, idx, max_new_tokens, temperature=1.0, top_k=None):
for _ in range(max_new_tokens):
# if the sequence context is growing too long we must crop it at block_size
idx_cond = idx if idx.size(1) <= self.config.block_size else idx[:, -self.config.block_size:]
# forward the model to get the logits for the index in the sequence
logits, _ = self(idx_cond)
# pluck the logits at the final step and scale by desired temperature
logits = logits[:, -1, :] / temperature
# optionally crop the logits to only the top k options
if top_k is not None:
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
logits[logits < v[:, [-1]]] = -float('Inf')
# apply softmax to convert logits to (normalized) probabilities
probs = F.softmax(logits, dim=-1)
# sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1)
# append sampled index to the running sequence and continue
idx = torch.cat((idx, idx_next), dim=1)
return idx
还有权重衰减,和减小block size 大小代码。
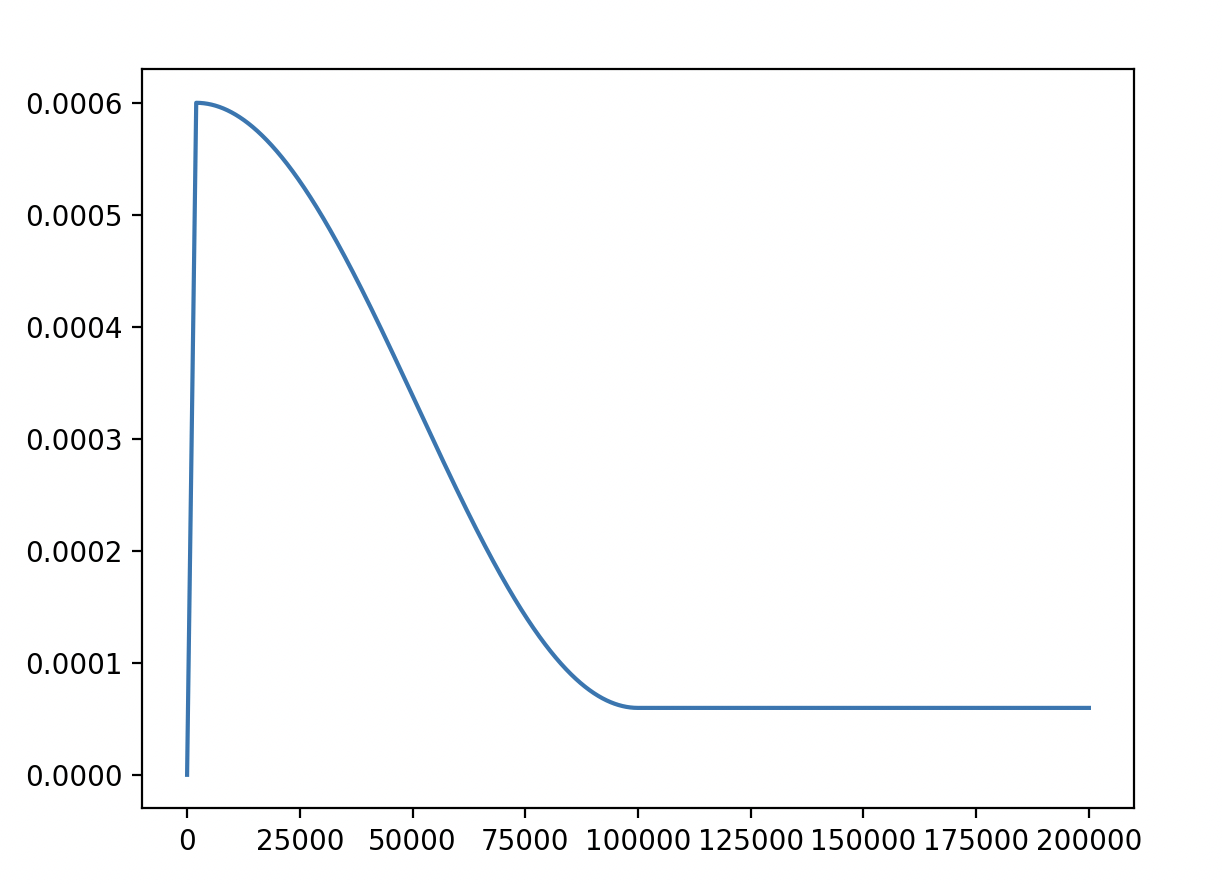
train
learning_rate = 6e-4
warmup_iters = 2000
lr_decay_iters = 100000
min_lr = 6e-5
def get_lr(iter):
# 1) linear warmup for warmup_iters steps
if iter < warmup_iters:
return learning_rate * iter / warmup_iters
# 2) if iter > lr_decay_iters, return min learning rate
if iter > lr_decay_iters:
return min_lr
# 3) in between, use cosine decay down to min learning rate
decay_ratio = (iter - warmup_iters) / (lr_decay_iters - warmup_iters)
assert 0 <= decay_ratio <= 1
coeff = 0.5 * (1.0 + math.cos(math.pi * decay_ratio)) # coeff ranges 0..1
return min_lr + coeff * (learning_rate - min_lr)
如上参数的学习率衰减曲线。