- Published on
邻近搜索
邻近搜索
- Annoy:Approximate Nearest Neighbors Oh Yeah
- HNSW:Hierarchcal Navigable Small World graphs
- KD Tree:K dimentional Tree
- LSH:Locality Sensitive Hashing
大数据情景下的邻近搜索:淘宝搜图,歌曲识别,指纹匹配,搜索引擎
如何从海量文本中快速查找出相似文本?
Annoy
Annoy通过将海量数据建立成一个二叉树来使得每个数据查找时间复杂度是O(logn)
- 随机两点进行切分,得到左右子树


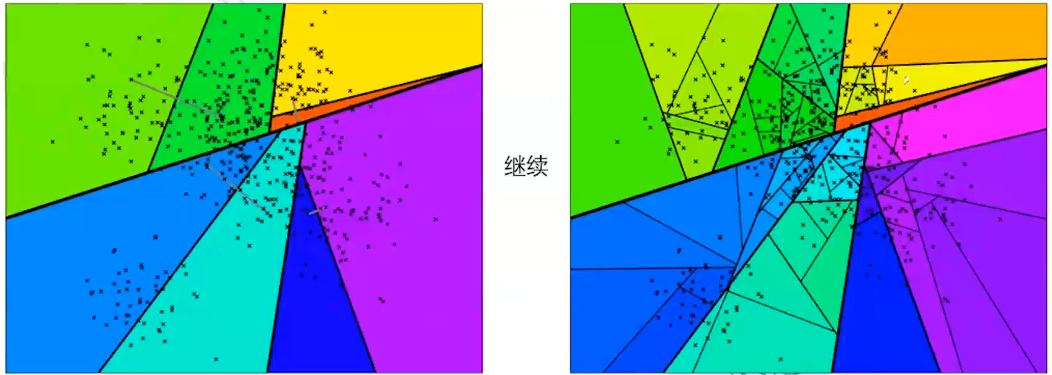
- 在划分的子空间中不停的递归迭代继续划分,直到每个子空间最多只剩下K个数据节点。K值由自己指定
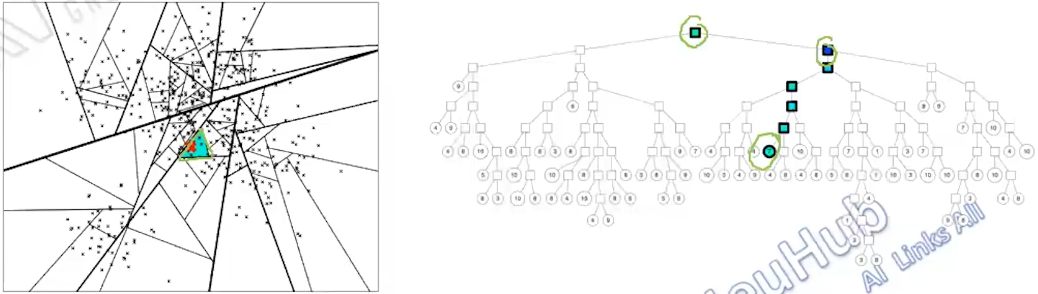
- 查找:不断查看此点在分割超平面的哪一边。从二叉树索引结构来看,即从根节点不停的往叶子节点遍历的过程。
这其中存在一些问题:
相邻空间中的某些点可能距离查找点更近,更相似。
查询过程最终落到叶子节点的数据节点数小于我们需要的Top N相似节点数目
trick1: 两边都遍历
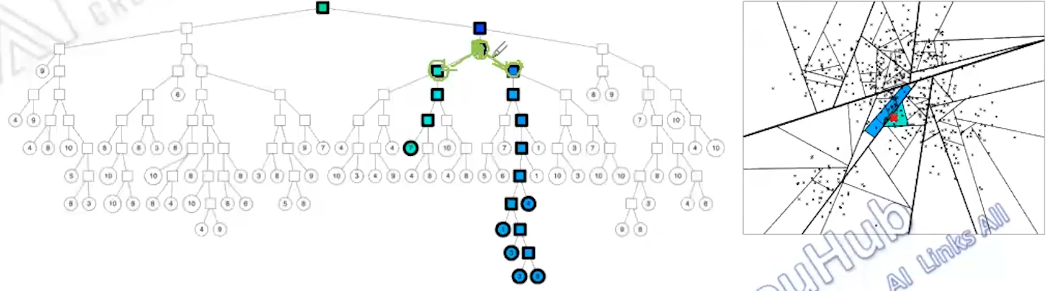
trick2:多棵树,多次随机过程生成多个树

【案例:腾讯词向量实战,通过Annoy进行索引和快速查询
https://www.52nlp.cn/腾讯词向量实战-通过annoy进行索引和快速查询】
HNSW
Hierarchical navigable Smalll World graphs
分层 可导航的
最朴素的图算法,近邻图Proximity Graph
思路: 构建一张图,每一个顶点连接着最近的N个顶点,Target(红点)是待查询的向量。在搜索时,选择任意一个定点出发,首先遍历它的相邻节点,找到距离和Target最近的某一节点,将其设置为起始节点,再从新的起始节点出发进行遍历,反复迭代,不断逼近,最后找到与target距离最近的节点时搜索结束。
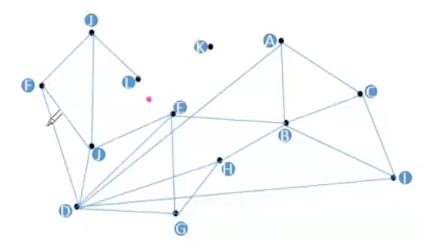
存在的缺点:
- 图中的K点无法被查询到
- 点之间没有连线,将影响效率
- 图中D节点的相邻(友节点)过多,增加了计算
- 如果初始节点选择很远,则计算量变大。增大了迭代次数
解决:NSW
某些点无法被查到 -> 规定构图时所有节点必须有友节点
相似点不相邻 -> 构图时所有距离相近到一定程度的节点互为友节点
某些节点友节点过多 -> 限制每个节点的友节点数
初始点选择很远 -> 高速公路机制 (跳表原理)skip lists
构建图:每次插入一个新的节点,更新图中所有节点友节点。(规定最多四个友节点)
- 增加高速公路机制
HNSW =NSW + 跳表

依次增加节点构建图,将较少节点构建的结果当做索引。寻找一个节点最近的节点时,先从节点数最少的图开始找(最上层图)最近的点。
类似于交通方式,飞机,地铁,步行;假如我们初始化为北京,现在要到上海,先乘坐飞机到上海,然后做地铁到目标附近,然后步行到达目的地。
code: https://github.com/nmslib/hnswlib