- Published on
TranSmart-笔记
交互式机器翻译
2 System Features
主要功能 及其 采用的技术:
-
词级别 自动补全;在英文单词输入的场景下,只用输入开头的几个字母,就可以生成几个候选单词,提高单词输入的效率
- 词汇约束(lexical constraints)
- word autocompletion
-
句子级别 自动补全;只需要提供部分单词翻译(提供的单词不需要保证连续),系统通过自动生成剩余单词完成翻译
- Generic Translation Model
- NMT with Lexical Constraints
-
增强翻译记忆 ,根据翻译历史生成翻译记忆,避免相似句子同类错误的产生。
- Generic Translation Model
- Translation Memory
-
其他的功能
- Document Translation
- Image Translation
- Terminology Translation
- 根据词频,长度比例,词频识别,过滤掉100万的网上爬取术语,产生出200万的术语terms
- Bilingual Examples:构建了一个2亿的句子检索,给用户展示3条输入相似句子。
3 Implemented Techniques
3.1 Generic Translation Model
使用24-layer encoder 和 6-layer decoder, hidden size 1024
使用2亿中英句对,batch:46万token
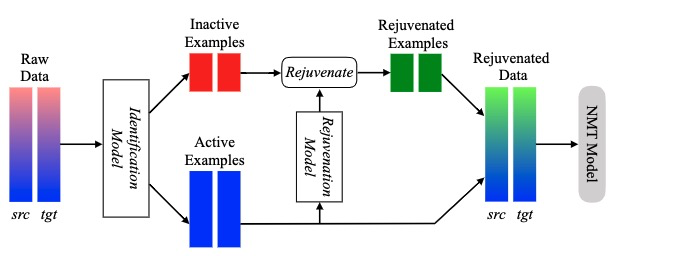
Data Rejuvenation
Data Rejuvenation: Exploiting Inactive Training Examples for Neural Machine Translation
重新利用对模型性能贡献较小的非活动训练示例进行训练,增加模型性能。
Data Augmentation
数据增强的做法通常有(self-training 和 back translation),作者经验说基于大规模单语数据随机抽取子集构建合成数据,是次优的。
作者改进了抽样过程,大概率选择不确定性较高的句子,进行抽样。不确定性较低的句子通常对应简单的翻译模型,不会带来额外的收益。Self-Training Sampling with Monolingual Data Uncertainty for Neural Machine Translation
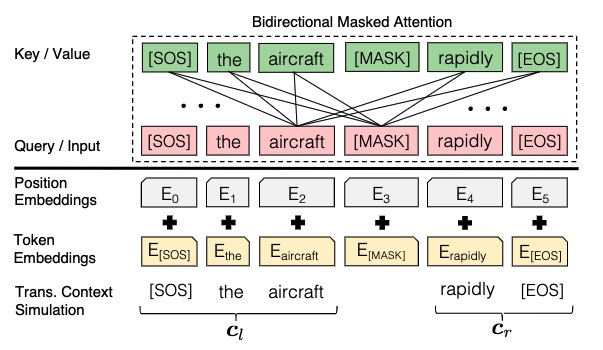
3.2 General Word-level Autocompletion
作者将单词自动补全分解为两个部分,基于原序列x和翻译上下文c对单词w的分布进行建模$P(w|x,c_l,c_r;\theta)=softmax(\phi(h))[w]$h是[MASK]的变量,然后线性映射到词表大小,然后基于该分布和人类键入的序列s找到最可能的单词w(这个训练数据通过训练样本生成,非标注)。
3.3 Sentence-level Autocompletion by Lexical Constraints
两种:硬约束,通过优化解码算法,权衡质量和速度。
软约束:将词语约束进行编码,然后decode的时候用。
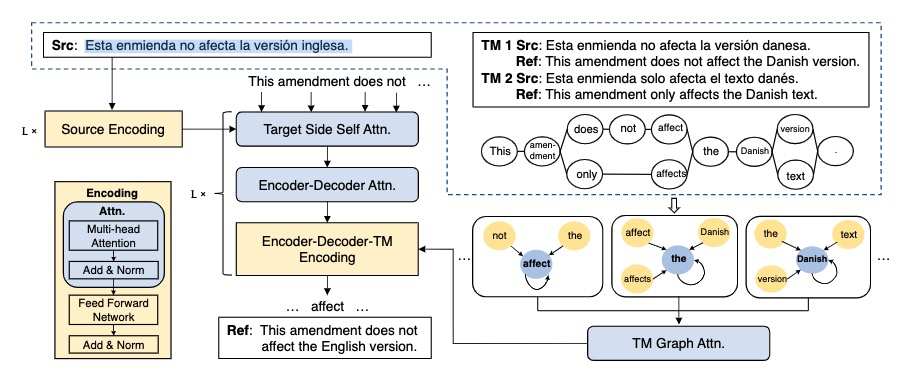
3.4 Graph based Translation Memory
Graph Based Translation Memory for Neural Machine Translation
3.5 others
word alignment
由于GIZA++内存消耗问题,作者使用HMM-based word alignment
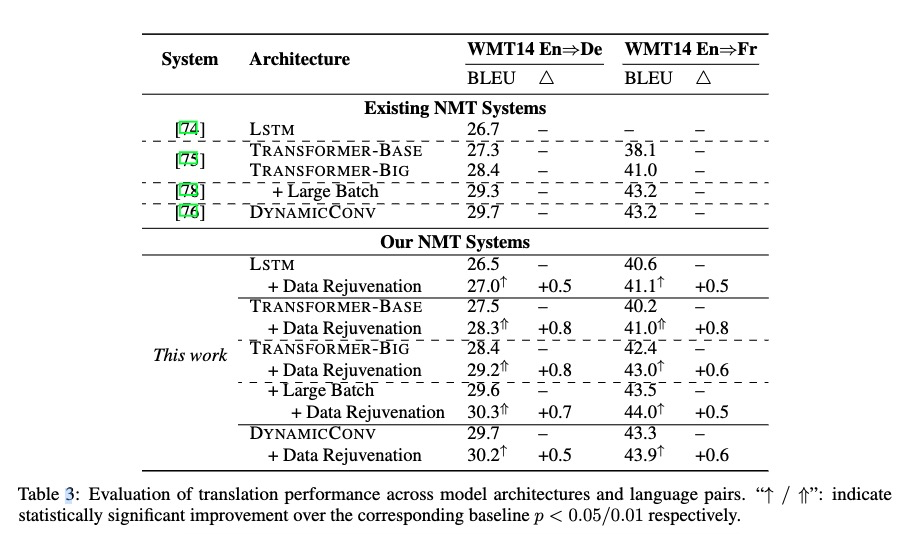
5 System Evaluation
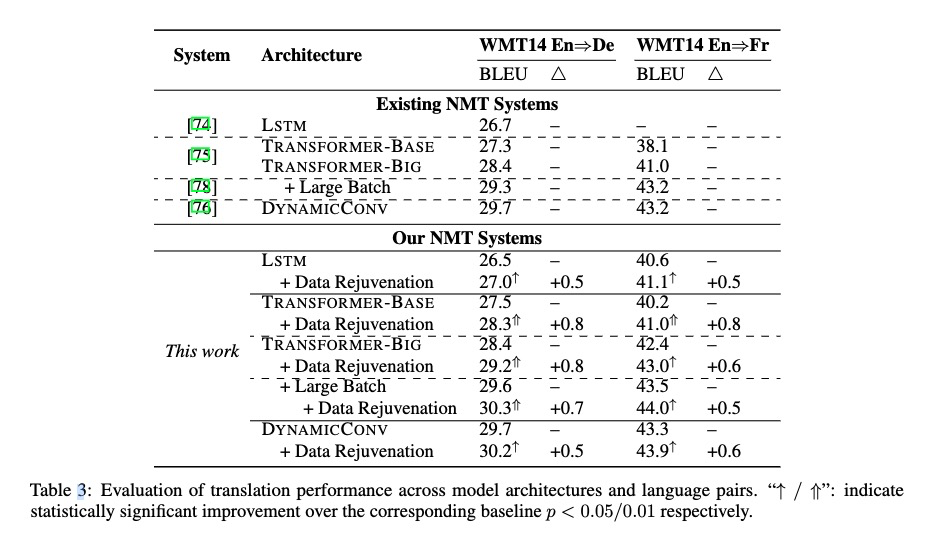
word-level 准确率有提升。
基于图的翻译记忆集成到Transformer模型与原始模型相比,带来了3个BLEU点的提升