- Published on
笔记-Improving_Neural_Machine_Translation_by_Bidirectional_Training

核心idea:使用双向模型作为单向模型的初始化。
将src->tgt数据 组合为 src+tgt -> tgt+src进行第一步(早期)(预)训练,然后再使用src->tgt训练。训练不修改模型结构,不增加额外的训练损失。
在8个语言对(数量160k-38M)上提高了SOTA的性能。
在总训练步数的1/3处停止了训练
BPE 32K
beam size 5 ,length penalty 1.0
大batch size,458k
训练细节:

作者验证了不同的early-stop step,都有较好的性能。选出一个简单有效的1/3。
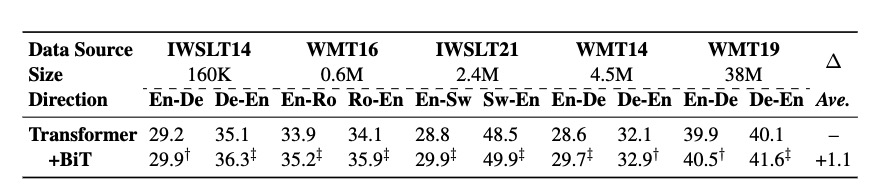
针对不同训练数据集大小的验证
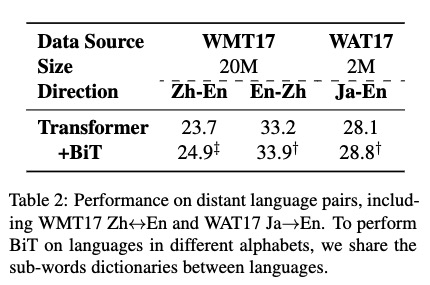
针对远距离语言对的验证
增加了三种数据操作查看BLEU,Tagged Back Translation(BT),Knowledge Distillation(KD), data diversification(DD)
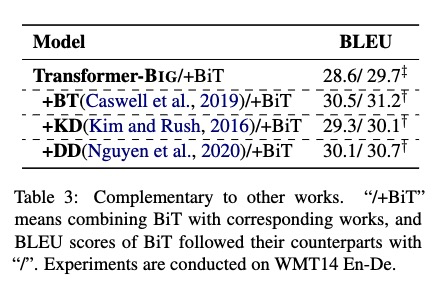
与其他的模型进行了比较

作者还证明了,BiT能够提高对齐质量,和低资源场景模型效果。
经过tensor2tensor Transformer复现BiT方法,结果BLEU 提升均值 1.1。