- Published on
GEC语法错误纠正-GECToR
GECToR – Grammatical Error Correction: Tag, Not Rewrite
作者设计了语法纠错token变换的标签,采用Berts+linear*2+softmax序列标注模型进行迭代GEC,推理速度快,并且采用三步训练和推理机巧提高模型新能。
Abstract
三步训练过程:
- 在合成数据上预训练
- 两步微调:
- 在错误数据微调
- 组合错误,正确数据进行微调
结果:http://nlpprogress.com/english/grammatical_error_correction.html
github:https://github.com/grammarly/gector
1. Introduction
基于NMT GEC系统存在推理慢,需要大量训练数据,不可解释,需要额外的工作来解释纠正的错误类型。
2. 数据
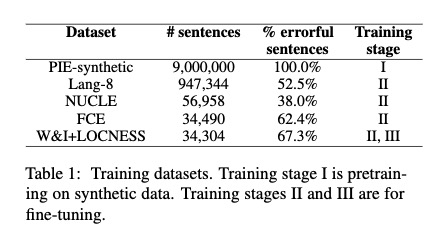
合成数据:https://github.com/awasthiabhijeet/PIE/tree/master/errorify
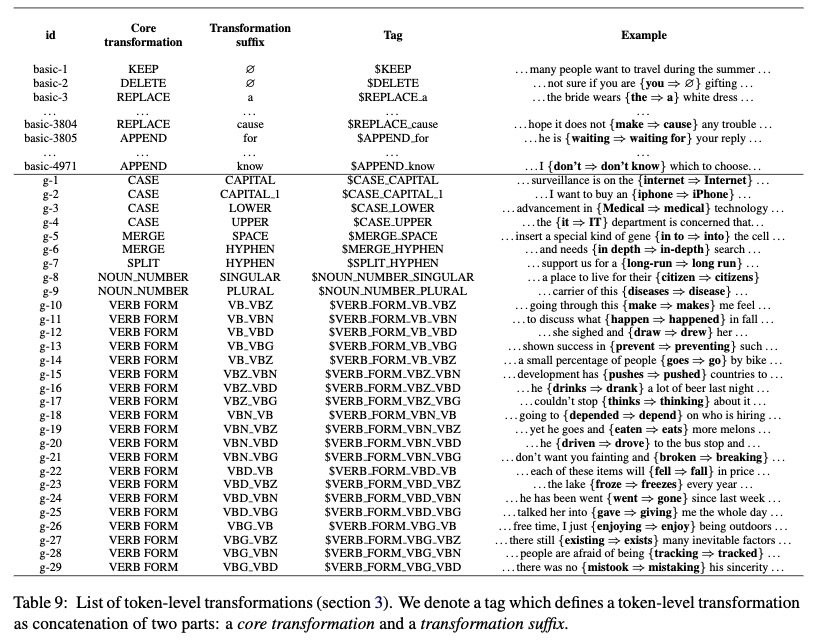
3. Token-level transformations
基础变换
tag $KEEP: 保持当前token不变
tag**$DELETE**: 删除当前token
tag $APPEND_t1 : 在当前token xi后面增加t1 token
tag $REPLACE_t2: 用token t2替换当前token xi
g-transformations
执行特定任务的操作
CASE tags: 改变大小写
MERGE tags: 合并当前token和下一个token
SPLIT tags:将当前token分为两个
tags NOUN NUMBER / VERB FORM 包括单数名词转换为复数,规则不规则动词形式的转变,时态等
动词变化使用https://github.com/gutfeeling/word_forms/blob/master/word_forms/en-verbs.txt变化字典。
Eg: gogoes, $toekn{0}_token_1$表示token0到token1的转换。VB_VBZ,同理也会有VBZ_VB.
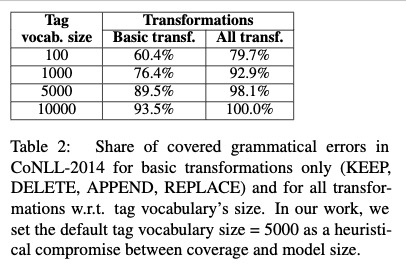
所有的token变化类型:
在CoNLL-2014上验证变化类型的错误覆盖率
预处理
Step1:将输入(错误句子)的每一个token映射为目标句子的零个(删除)或多个token
A -> A
ten -> ten, -
years -> year, -
old -> old
go -> goes, to
school -> school, .
通过最小化编辑距离使得g变换的代价为0.
Step2:添加标记
A -> A $KEEP
ten -> ten, - $KEEP $MERGE*HYPHEN(连字符)
years -> year, - $NOUN_NUMBER_SINGULAR(单数) $MERGE_HYPHEN
old -> old $KEEP
go -> goes, to $VERB_FORM_VB_VBZ $APPEND_to
school -> school, . $KEEP $APPEND*{.}
Step3: 为每个source token保留一个变换(如果两个变换第一个是 KEEP那就去掉)
A -> A $KEEP
ten -> ten, - $MERGE*HYPHEN(连字符)
years -> year, - $NOUN_NUMBER_SINGULAR(单数) $MERGE_HYPHEN
old -> old $KEEP
go -> goes, to $VERB_FORM_VB_VBZ $APPEND_to
school -> school, . $APPEND*{.}
4. Tagging model架构
bert类似的模型上面加两层线性层和softmax。
根据不同的pretraining选择不同的subword算法,并且将token subword后的第一个字词部分输出传递到下一层。
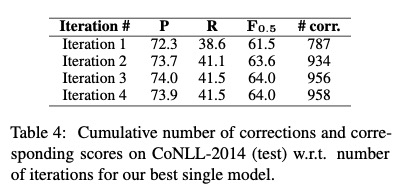
5. 迭代方法
上面例子中,years先是变为year然后再通过连字符链接。所以模型也是迭代预测。

通常大部分错误在前两次tagging中已经纠正了。
6. Experiments
三步训练阶段
第一步合成数据。第二部有错数据微调,第三部有错和无错数据微调。
两步微调对性能的提升是很大的。
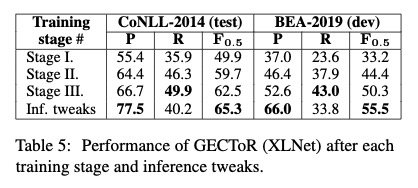
early stop 条件:3epoch 或10k没有提升的更新。
训练1,2阶段前两个epoch冻结编码器权重,并且batch size大于64可以加快收敛并提高性能。
不同预训练模型作为encoder
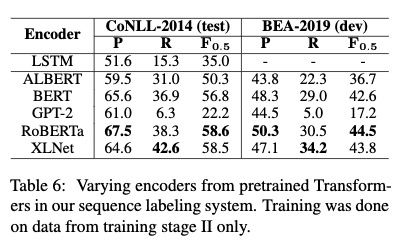
RoBERTa和XLNet效果最好。
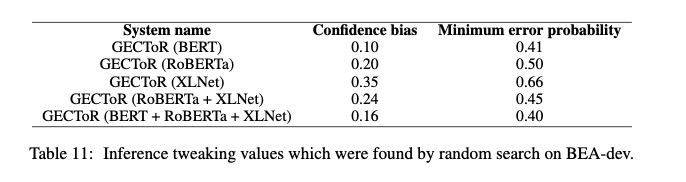
推理调整
对$KEEP添加了永久的正置信度偏差。负责不更改源令牌。训练时错误的句子多,推理过程中模型可能会对KEEP的得分较低。
添加了句子级最小错误概率,减少召回率来实现更好的F_0.5 score,如上上表(Table5)
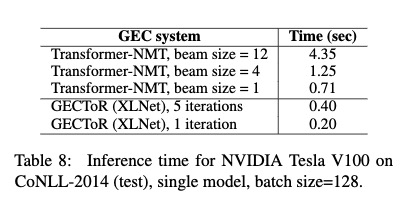
推理速度
M2输出为incor cor文件脚本
import argparse
# Apply the edits of a single annotator to generate the corrected sentences.
def main(args):
m2 = open(args.m2_file).read().strip().split("\n\n")
out = open(args.out_corrected, "w+")
origin = open(args.out_original, 'w+')
# Do not apply edits with these error types
skip = {"noop", "UNK", "Um"}
for sent in m2:
sent = sent.split("\n")
cor_sent = sent[0].split()[1:] # Ignore "S "
original_sent = " ".join(cor_sent)
edits = sent[1:]
offset = 0
for edit in edits:
edit = edit.split("|||")
if edit[1] in skip: continue # Ignore certain edits
coder = int(edit[-1])
if coder != args.id: continue # Ignore other coders
span = edit[0].split()[1:] # Ignore "A "
start = int(span[0])
end = int(span[1])
cor = edit[2].split()
cor_sent[start + offset:end + offset] = cor
offset = offset - (end - start) + len(cor)
out.write(" ".join(cor_sent) + "\n")
origin.write(original_sent + '\n')
if __name__ == "__main__":
# Define and parse program input
parser = argparse.ArgumentParser()
parser.add_argument("m2_file", help="The path to an input m2 file.")
parser.add_argument("-out_original", help="A path to where we save the output original text file.", required=True)
parser.add_argument("-out_corrected", help="A path to where we save the output corrected text file.", required=True)
parser.add_argument("-id", help="The id of the target annotator in the m2 file.", type=int, default=0)
args = parser.parse_args()
main(args)