- Published on
n-gram检索domain_Adaptation:_Non-Parametric_Adaptation_for_Neural_Machine_Translation
Non-Parametric Adaptation for Neural Machine Translation
作者提出了一个半参数方法,使MT新的domains上无需参数更新,依赖n-gram检索获得好的效果。
- 检索相似n-gram样本:基于IDF和dense vector
- 设计了新的架构编码source-target信息。让模型能够区分噪音,进行了消融分析
模型在异构数据,稀有短语的翻译能力弱,而微调会有灾难性遗忘问题,所以非参数方法就比较重要。作者说其他的检索方法有效可能是领域的狭窄导致翻译过渡依赖检索。
检索的目的是为了提高翻译质量,最大化句子相似度和翻译性能之间的影响还需要进一步实验。
检索方法
IDF句子检索

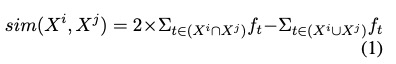
IDF N-gram检索
$X=(t^1,...t^T)$ 为了避免表示句子n-gram的数量
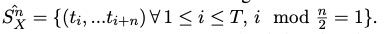
考虑重复,如果一个句子已经添加到检索集,要找下一个相似的句子。
每个句子检索到的邻居数量和长度成正比
N-gram向量
n-gram subword 的那部分求平均
新架构
架构
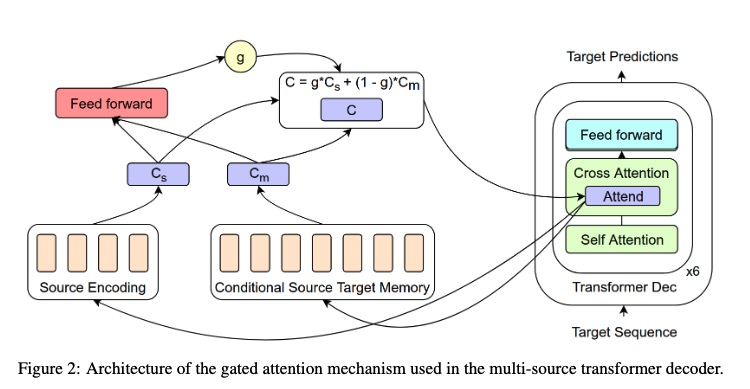
CSTM
其中Conditional Source Target Memory生成采用如下方法:
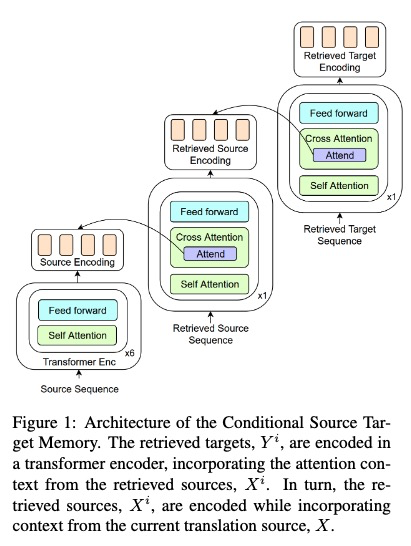
CSTM介绍:


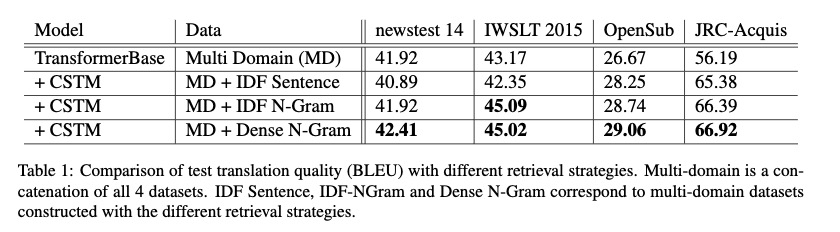
模型效果