- Published on
GPT3
Language Models are Few-Shot Learners
增大语言模型可以提高模型任务无偏(task-agnostic)和小样本学习(few shot)的能力.GPT3 178b参数的语言模型,参数量是之前语言模型的十倍。不需要梯度更新或fine tuning,在一些任务上(问答,填空,翻译)有不错的性能,
GPT3 通过few-shot learning对于一些数据集仍然困难。
还有个方法论的问题,如何在大数据量上训练模型。
简介
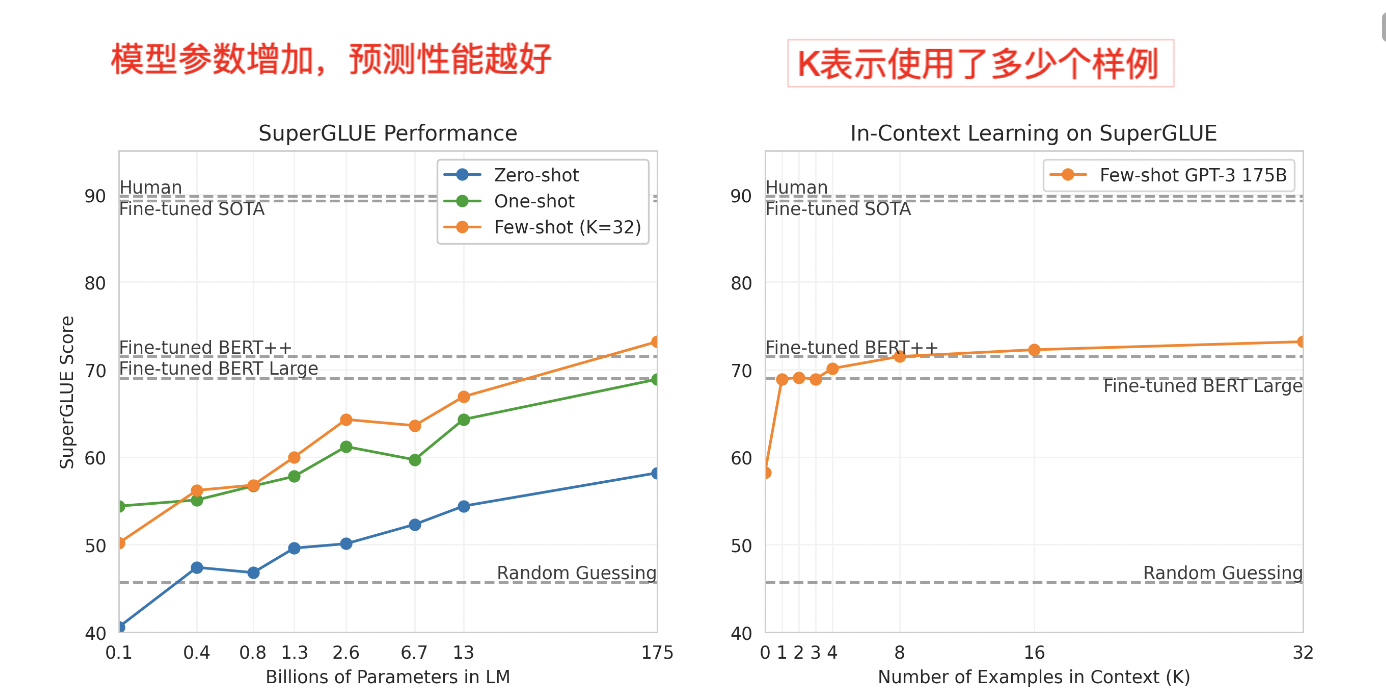
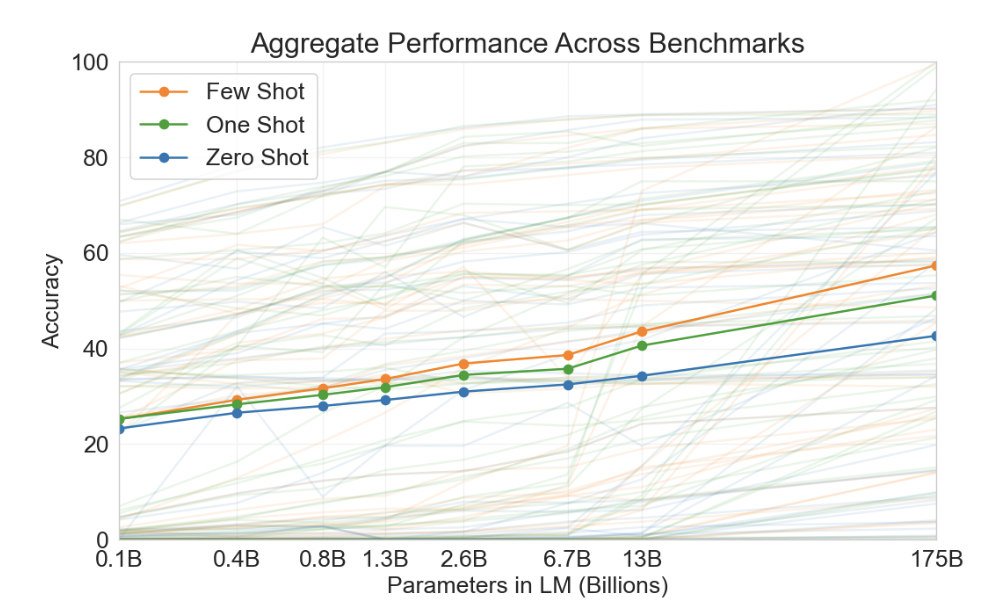
zero-shot性能随着模型大小的增加稳步提高,few-shot模型性能增加更快。较大的模型更擅长in-context learning.
方法
数据集,模型大小多样性,训练长度的拓展相对简单。 作者主要探索了在上下文中学习的不同设置:
- fine-tuning FT
- few-shot FS,给K个样本的例子(上下文和输出)和最后输出的上下文。few-shot主要的优势是减少了任务样本的数量。few-shot个数量K在10-100之间。
- one-shot 1S K=1
- Zero-shot
虽然在本人few-shot实现了最高性能。但是zero-shot和1S仍然是未来工作的重要目标。
模型和架构
训练了8种不同大小的模型,从123m到175b。
训练数据
CommonCrawl 高质量的数据
模糊重复数据删除 内部以及不同数据集之间。
Webtext以及网上数据语料Book1 和Books2, 和英语 Wikipedia。
训练过程
较大的模型通常可以使用较大的批量大小,需要较小的学习率。
结果
Language Models,Cloze, Completion Task
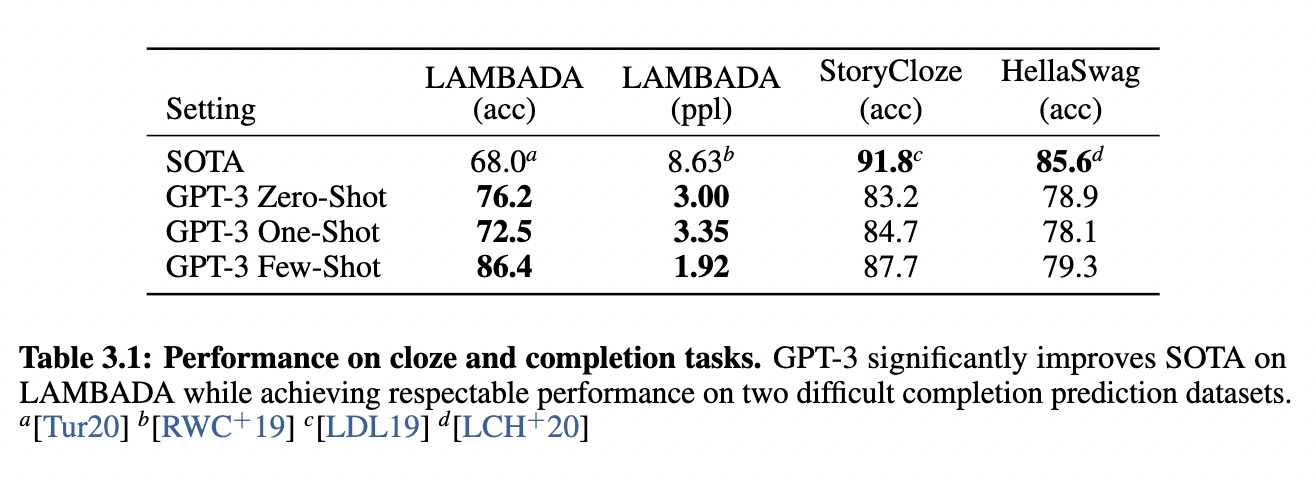
zero-shot GPT比SOTA高8%, 通过调整输入的format GPT3可以提升的更多(18%),例如fill-in-the-blank【Alice was friends with Bob. Alice went to visit her friend, . → Bob】
QA

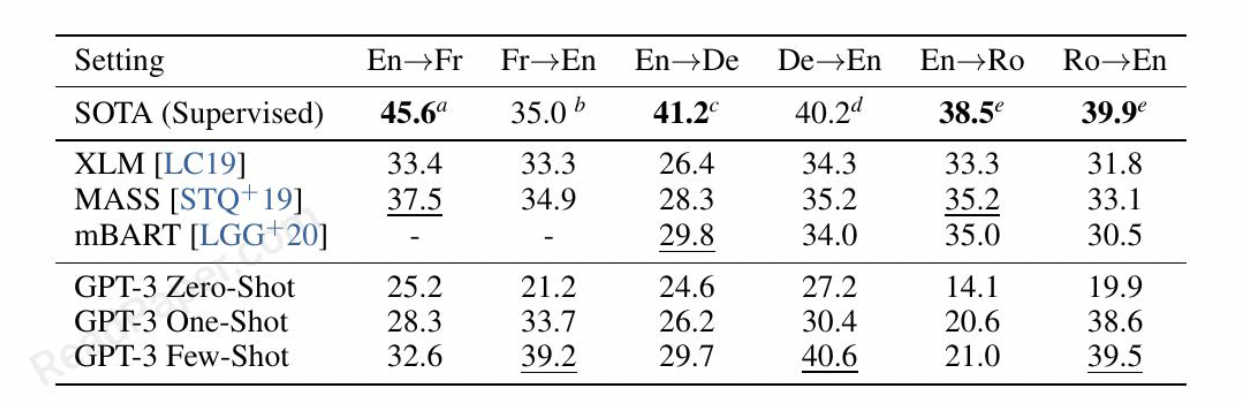
翻译
GPT3的训练数据主要由英文组成(字数比例在93%),也包括7%的非英语内容。
目标语言为英文的时候模型的输出能力好。
SuperCLUE
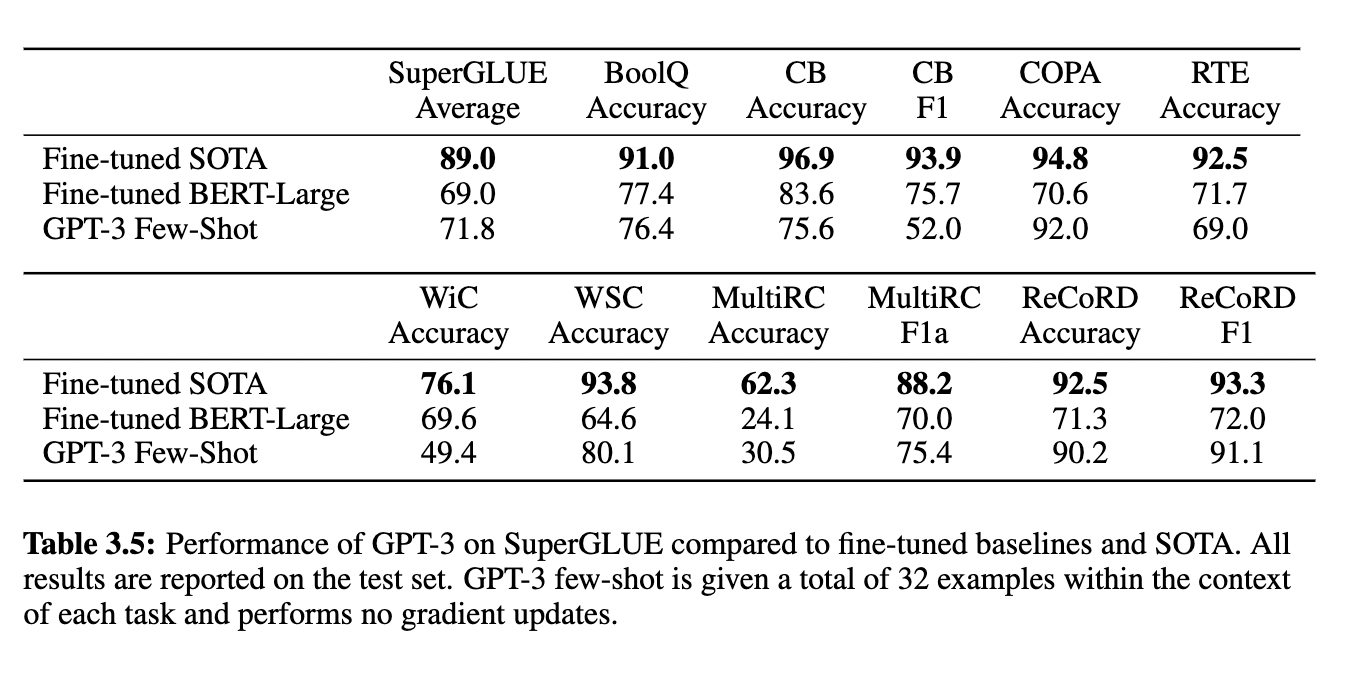
GPT3在八项任务中的四箱优于微调的Bert-learge,并且在两项任务上,GPT接近进过微调的110亿参数模型的SOTA。
Measuring and Preventing Memorization Of Benchmarks
数据集和模型大小比GPT2 数据集和模型大小大约两个数量级。包含common crawl 会增加污染和记忆的可能性。
数据量巨大, GPT3 也不会过拟合。
通过13-gram的去重,在干净的基准数据集上测试,结果与原始分数相似,表明即使存在污染,也不会对报告产生重大影响。
局限性
在文本合成方面,GPT-3样本有时仍然在文档级别上语义上重复,在足够长的段落中开始失去连贯性,自相矛盾,偶尔包含不符合逻辑的句子或段落。我们的发行版存储库包含无组织的无条件样本。
实验不包括双侠架构或其他训练目标,在受益于双向性的任务上,可能表现得更差。例如填空,比较两部分内容,根据长文本生成简短的答案。
GPT3的目标是对每一个token都一视同仁,缺乏一个概念,什么是重要的预测,什么是不重要的预测。语言系统可能更好的被认为是采用目标导向的行动,不仅仅是进行预测。大型预训练模型没有基于其他经验领域如视频或现实世界的物理交互,缺乏大量关于世界的上下文。有希望从人类那里学习目标函数Fine-tuning language models from human preferences, 2019.。利用强化学习进行微调。
GPT3的大小使其部署具有挑战性,特定于任务的蒸馏值得在这个新规模上进行探索。[Distilling the knowledge in a neural network]
instructions
Training language models to follow instructions with human feedback
大型语言模型可能会生成不真实的、有毒的或对用户没有帮助的输出。 换句话说,这些模型与其用户不一致。可以通过根据人类反馈进行微调,使语言模型与用户对各种任务的意图保持一致
1.3B 参数 InstructGPT 模型的输出优于 175B GPT-3 的输出,尽管参数少 100 倍。 此外,InstructGPT 模型显示了真实性的提高和有毒输出生成的减少,同时对公共 NLP 数据集的性能回归最小。 尽管 InstructGPT 仍然会犯一些简单的错误,但我们的结果表明,根据人类反馈进行微调是使语言模型与人类意图保持一致的一个有前途的方向。