- Published on
自编码-自回归_BERT-GPT-LLM_
自回归 和 自编码
Auto encoding: 输入是自己输入也是自己 。模型对输入进行特征编辑,再根据特征编码重构输入。
Denoising Auto encoding: 输入是自己+噪音,输出是自己。bert
输入[MASK] [MASK] is a city, 输出New York. 通常假设MASK之前是独立的,但是真实情况不是独立的。并且训练和测试时候会有gap。训练时候有[MASK],但是微调,预测时输入可能没有[MASK]
$$\max \theta \log p\theta(\overline{\mathbf{x}} \mid \hat{\mathbf{x}}) \approx \sum_{t=1}^T m_t \log p_\theta\left(x_t \mid \hat{\mathbf{x}}\right)$$
$m_t$是0-1之间的超参
$\overline{\mathbf{x}}$代表被mask的单词,$\hat{\mathbf{x}}$没有被mask的单词
$P(New, York | is,a,city) \approx m_1 P(New|is,a,city)* m_2 P(York| is,a,city)$
优点:双向模型
缺点:训练和预测有偏差。独立假设。
Auto regressive:
$\max \theta \log p\theta(\mathbf{x})=\sum_{t=1}^T \log p_\theta\left(x_t \mid \mathbf{x}_{\leq t}\right)$
类似于语言模型
优点:没有偏差。
缺点:单向模型。不能利用句子后面的信息。
模型架构
模型任务
BERT
bert finetuing
Sentence Pair Classfication:两段文本A,B之间的关系
为什么bert CLS在为finetuing时作为sentence embedding 很糟糕?
预训练CLS embedding是用来做NSP任务的输出。 所以是NSP任务的高阶feature。描述两段文本是否构成上下文关系,所以直接用会很糟糕。
Single Sentence Classificaiton:
原本bert输入是两个句子 中间有个[sep], 这个任务只需要输入一个句子
Question Answering Task
根据问题在文章里面找答案。知道答案的开头和结尾就可。
输入:Question+[SEP]+ Paragraph
输入:Paragraph 上的 start end标注。
Single Sentence Tagging Task
NER:每个Token的分类任务。
ALBERT
A lite BERT for language Understanding
- 输入矩阵分解
- 共享attention 权重
- NSP 改造为SOP(sentence order )
- Dropout意义不是很大
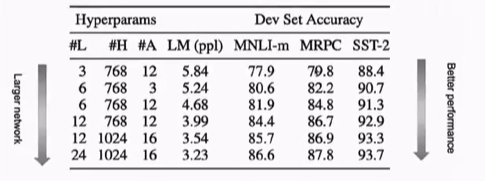
深度宽度提升,表现越好
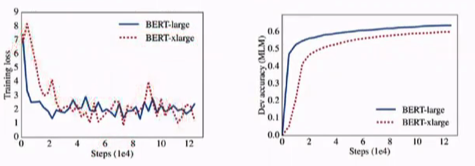
但是当bert-large 到bert-xlarge,准确率有一个很大的下降。

bert参数两部分
- attention feed-forward block:12 _ L _ H * H (L: layer size ; H hidden size)
- token embedding projection block: V * E . (V: vocab size, E: embedding size 通常和 hidden size是相同的)
矩阵分解重新构造参数,目的:将one hot 变为 hidden
V _ H = V _ E + E * H
原来30K _ 768 变为 30k _ 128 128 * 768
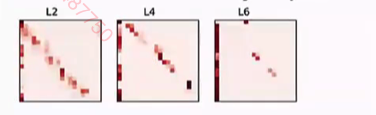
不同层之间的attenion是相似的。 如下图。所以可以让每一层都共享参数。
12 _ L _ H _ H -> 12 _ H * H
shared -FFN 时候,模型性能会有明显的下降。
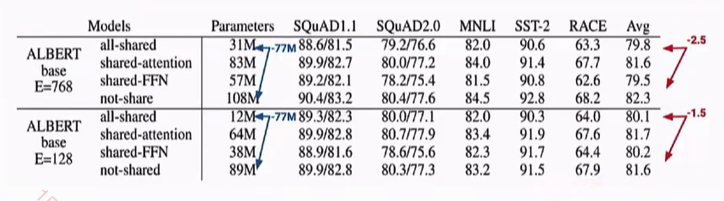
对AlBERT增加深度时,性能也会下降。并不是越深越好。能是数据量的原因
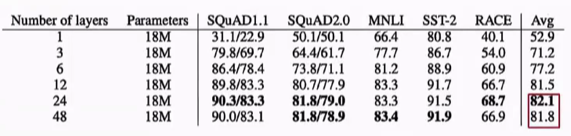
SOP sentence order prediction,A B两个句子谁应该在前面。

不使用Dropout 有一点点提高。 Dropout是为了防止过拟合。模型还没达到拟合?可能训练不充分

RoBERTa
A robustly Optimized Bert Pretraining Approach
重新定义训练任务,增加语料,训练步数
Bert 表现不好的原因:作者认为bert没有得到充分的训练
roberta增加了词典 从30k到50k (BPE)
Bert在预处理数据时,已经做好了MASK,所以不论训练多少epoch,MASK都是不改变的。roberta采用dynamic masking,每一次训练重新选择15%的masking。
提高batch size,有一点点提升
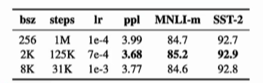
增大语料,训练更长
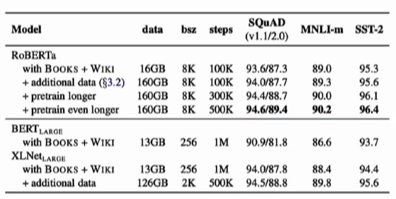
NSP不是必须要做的。
FinBert
Financial Sentiment analysis with pre-trained Language Models
金融领域 情感分析预训练模型
general的模型直接用于金融领域,输入数据分布不同。
在原来bert上继续训练,防止模型灾难性遗忘。
- 倾斜的三角形学习率,线性增加学习率,线性衰减学习率
- 不同layer的参数,使用不同的学习率,越低层使用更低的learning rate。低层局部特征的调整小。高层全局特征。
- 训练过程中,保持一些参数不调整。
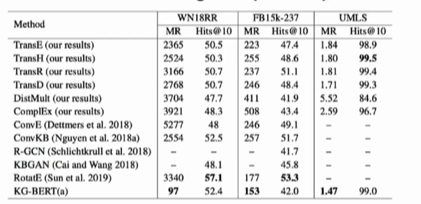
K-Bert KG-bert
K-BERT: Enabling Language Representation with Knowledge Graph
KG-bert :完成knowledge graph 做知识图谱的补全。
知识图谱引入bert中
知识推理 任务上,
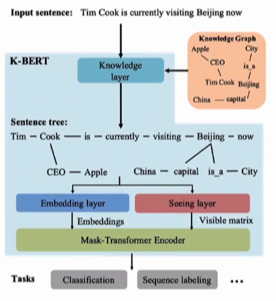
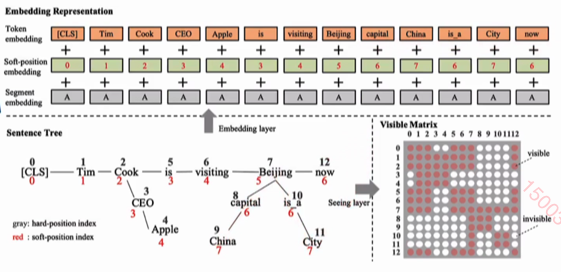
将sentence Tree 作为序列输入模型
seeing layer:
通过visible Matrix 控制:
- 主干上的token 只能看主干的信息
- 主干上有knowledge,则可以看主干+ 自己的分支信息。
- 分支,则只能看自己和主干上特定的token
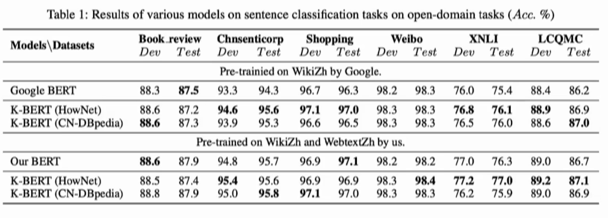
也做了消融实验,证明soft embeding和visible matrix 是有效的。
KG-bert 输入三元组,
输入:我(object) 是(relation) 人(subject), 输出 1。 输出是一个分类任务。判断输入是否有关。
也可以输入 object subject,输出 relation。
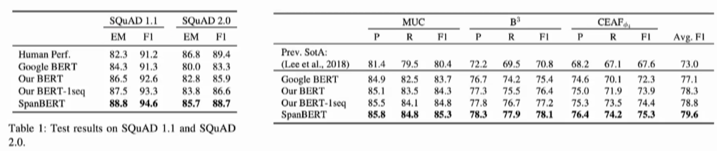
SpanBert
更加优化做mask的场景,mask长度,其他预训练任务
Improving Pre-training by representing and predicting spans
bert是预测一个token, 这里是预测一个span(一小段token)。比如百度的ERNIE。
作者提出了一个更好的方案。SBO span boundary objective。也取缔了NSP任务。
- span masking
span 的长度怎么取? 根据几何分布选择一个长度。均匀分布决定mask的起始位置。
依据集合分布 期望长度是 3.8,三四个词。
- Span boundary objective
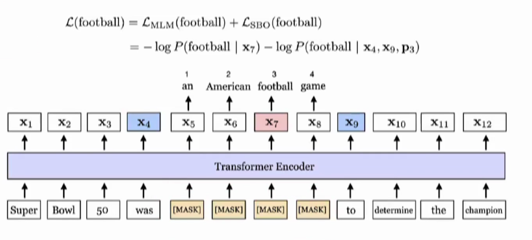
利用span周围的两个词的信息,预测中间的词。 以前是利用周围所有的信息来预测mask。
对于上图预测$x_7$的损失:一部分是football的 MLM的损失,另一部分是 SBO利用span周围两个词的信息。
- 是否需要NSP?
解释1: 相比于两个句子拼接,一个长的句子模型可以更好的获得上下文信息
解释2: NSP是负例的情况下,会给MLM带来很大的噪声。预测不同句的mask时,会携带另一句的信息。
GPT
Auto regressive
masked self attention ,只能看到$x_{t}$之前的信息。
训练GPT只需要训练语言模型

 GPT可以得到一个文本的表征向量。可以做一些分类,相似性判断等任务
GPT可以得到一个文本的表征向量。可以做一些分类,相似性判断等任务
Summarization:
输入 article + summarize标识 + 标准答案 作为训练数据
预测的时候, 输入 aiticle + summarize 标识 模型预测出标准答案。
XLnet
make autoregressive bi-directional
对输入句子进行排列组合。
New York is a city
York is New a city
New city is a York
不考虑顺序,让模型看到前后的信息
Permutaion Language Modeling
$\max \theta \mathbb{E}{\mathbf{z} \sim \mathcal{z}T}\left[\sum{t=1}^T \log p_\theta\left(x_{z_t} \mid \mathbf{x}{\mathbf{z}{<t}}\right)\right]$
x序列 1,2,3
抽样Z {[1,2,3],[2,3,1],[3,2,1]}
对抽样中的序列期望概率最大。
通过attention 控制每次可以看到的信息。解决gpt依赖问题,可以看到前后信息。
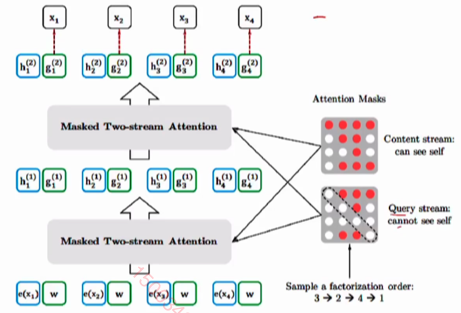
content stream: can see self 预测别人的时候,需要看到自己的全部信息
Query stream canot see self:预测自己的时候,只能看到自己的位置。代替了mask。
来源于 transformer XL, 相对位置编码 + RNN,让模型能够接受长文档输入。
LLM
https://zhuanlan.zhihu.com/p/597586623
2013年 深度学习被引入 NLP
LSTM, CNN, Attention :训练数据总量不高, 模型特征提取能力不高
2017年 self attention 提出。(Google)
中间任务:中文分词,词性标注,NER,句法解析,指代消解,语义Parser
看法:中间任务出现是NLP技术发展水平不够高的体现。对于MT,直接做好比较困难, 分而治之将任务分为:分词,词性标注,句法分析等阶段。
任务:
- NLG GPT+ zero / Few shot Prompt
- NLU Bert + finetuning
绝大部分都忽视了GPT这条路线的潜力。
202005 GPT3
GPT3.0 类模型:PaLM,GLaM,Gopher、Chinchilla、MT-NLG、LaMDA等
zero shot prompt初衷是人类和LLM的理想接口。目前发现LLM并不能很好的理解,所以有了few shot prompting(过渡期技术)。
few shot prompting (incontext learning)
chatgpt 让 instruct 取代了prompting,将人类偏好知识注入GPT3.5
”大多数领域独有的问题,大概率只是缺乏领域知识导致的外在表象,只要领域知识足够多,领域问题也可以被解决掉“
增加与训练数据的多样性,涵盖越多的领域,子领域会纳入LLM的技术体系。
LLM学到了什么:
语言类知识:模型低层
世界知识:事实型 常识性知识。 中层
BERTnesia: Investigating the capture and forgetting of knowledge in BERT 如果Transformer模型层深增加,能够学习到的知识数量逐渐以指数级增加
When Do You Need Billions of Words of Pre-training Data? 用1000万到1亿单词的语料,就可以学好句法语义等语言学知识